豆包被微信封杀后,我自己做了一个微信群聊Agent

最近豆包Agent手机爆火,让能够操作手机的AI Agent走进了大众视野。借助大模型和系统层面的深度整合,用户凭借自然语言就能实现跨应用的复杂操作,交互体验相当惊艳。
但很快,各大厂商开始围剿。用豆包操作微信会直接触发风控,豆包也不得不停止了相关功能。
我一直在关注Agent在移动端的技术进展。原因很简单:手机是每个人每天接触时间最长的设备,也是最重要的流量入口。
谁掌握了手机上的AI交互,谁就可能赢得下一个时代的入口。
而AI的出现,正在改写现有的格局。
正好最近有个需求——想在自己的羽毛球群里弄一个AI助手,能够回答群友的问题。既然豆包不能用了,那就自己动手做一个。
1 为什么选择Agent方案
1.1 传统方案的困境
实现微信机器人,传统方案是Hook——对微信客户端进行逆向,拦截底层函数,直接调用内部API。这种方案有几个致命问题:
- 风控风险高:直接操作底层API,容易被检测和封禁
- 维护成本大:每次微信版本更新都要重新适配
- 技术门槛高:需要逆向工程能力
现有的开源微信机器人框架基本都已经失效。
1.2 Agent方案:让AI像人一样操作
换一个思路:既然直接调API会被检测,那就不调API。让AI像人一样,通过"看屏幕"和"模拟点击"来操作微信。
这就是Agent方案的核心思路:
- 眼睛 = VLM视觉理解 + OCR文字识别
- 大脑 = 大模型智能决策
- 手 = ADB模拟点击和输入
在操作系统层面模拟人的行为,代码层面很难区分是真人还是程序。而且这是通用方案,不会因为微信版本更新而失效。
| 维度 | Hook方案 | Agent方案 |
|---|---|---|
| 实现原理 | 逆向微信底层函数 | 操作系统层面模拟人的操作 |
| 风控风险 | 高 | 低 |
| 版本适配 | 每次更新都要适配 | 基于视觉识别,天然适配 |
| 开发难度 | 需要逆向能力 | 需要VLM和设备控制能力 |
2 项目架构
整个项目用Cursor辅助完成开发,采用清晰的分层架构设计。
2.1 整体架构
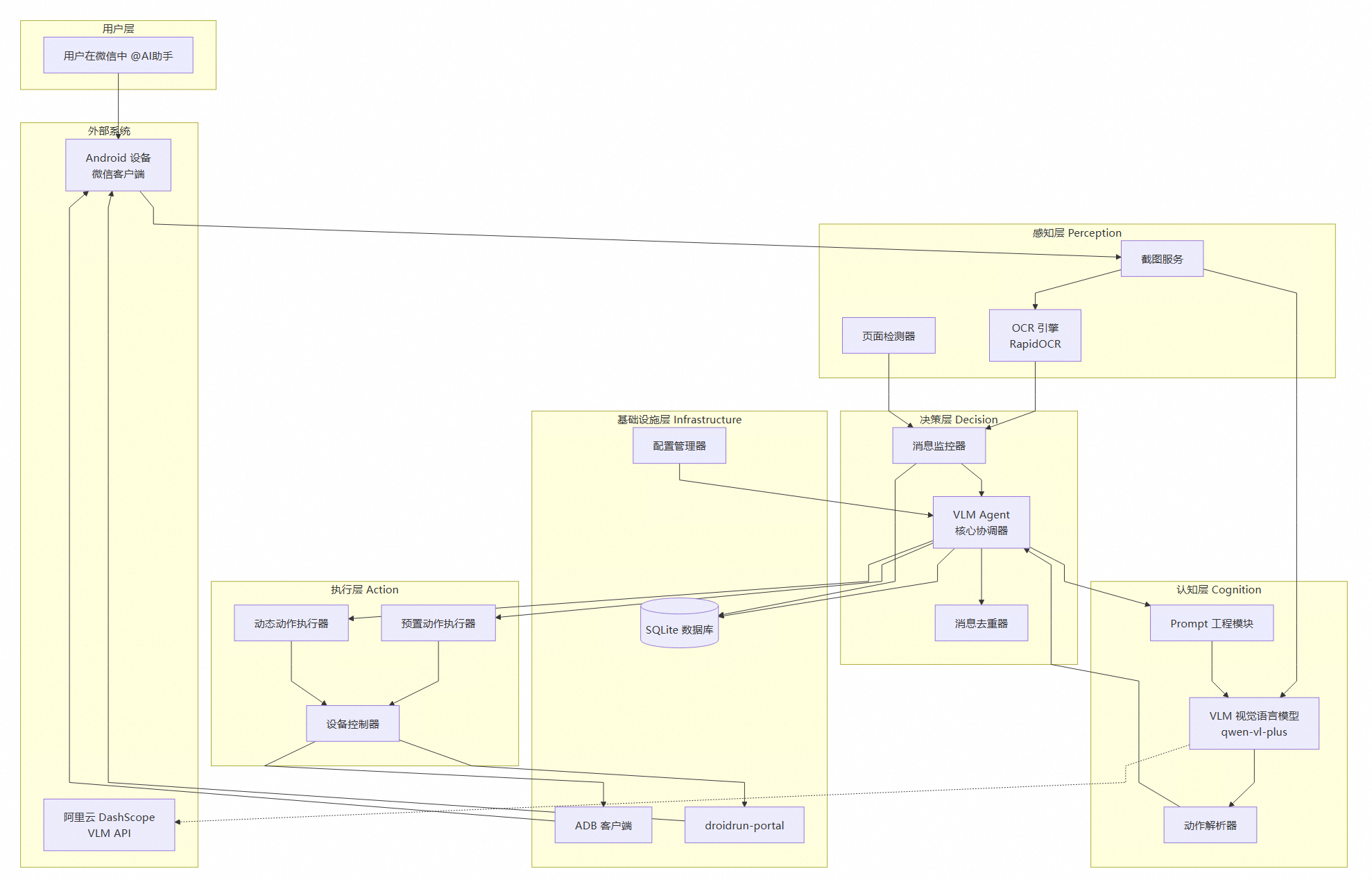
技术栈选型:
| 层级 | 技术选型 | 理由 |
|---|---|---|
| 视觉理解 | qwen-vl-plus | 多模态能力强,中文理解优秀 |
| 文字识别 | RapidOCR-ONNX | 比 PaddleOCR 在 macOS ARM64 更稳定 |
| 设备控制 | ADB + droidrun-portal | ADB 提供底层能力,Portal 支持中文输入 |
| 数据存储 | SQLite | 轻量级,零配置 |
2.2 设备控制:双通道架构
设备控制是整个系统的"手",采用 ADB + droidrun-portal 双通道架构:
graph LR
subgraph "DeviceController"
DC[统一接口]
end
subgraph "ADB 通道"
ADB[ADBClient]
ADB --> |shell| SHELL[input tap/swipe/keyevent]
ADB --> |pull| PULL[截图获取]
end
subgraph "Portal 通道"
Portal[PortalClient]
Portal --> |ContentProvider| CP[无障碍服务 API]
CP --> UI[UI 树获取]
CP --> KB[Droidrun Keyboard
中文输入]
end
DC --> ADB
DC --> Portal
为什么需要双通道?
| 能力 | ADB | Portal | 说明 |
|---|---|---|---|
| 点击/滑动 | ✅ | ✅ | 两者都支持 |
| 截图 | ✅ | ❌ | 只有 ADB 支持 |
| 中文输入 | ❌ | ✅ | ADB 的 input text 不支持中文 |
| UI 树 | ❌ | ✅ | 需要无障碍服务 |
| 系统按键 | ✅ | ✅ | 两者都支持 |
中文输入是一个关键技术点。标准 ADB 的 input text 命令不支持中文,系统通过 droidrun-portal 的自定义输入法解决:
|
|
2.3 消息解析:双路径策略
消息解析采用优雅降级的设计,优先使用 UI 树解析,失败时回退到 OCR:
graph TB
A[需要解析消息] --> B{UI 树可用?}
B -->|是| C[UI 元素解析]
B -->|否| D[OCR 识别解析]
C --> E{解析成功?}
E -->|是| F[返回结果]
E -->|否| D
D --> F
OCR 解析有个关键问题:可能将一条消息拆分成多个文本块。解决方案是基于 Y 坐标的文本块合并算法:
|
|
2.4 消息处理全链路
从用户发消息到 AI 回复,完整的处理链路如下:
3 核心技术挑战
架构设计好了,但在实际开发中还是遇到了不少问题。
3.1 挑战一:AI总是重复回复
这是开发过程中遇到的第一个头疼问题。
场景是这样的:用户发送消息A,AI开始处理;在AI还没回复完之前,用户又发送了消息B。这时候AI截图,看到了A和B两条消息,但A的回复还没发出去,于是AI认为A和B都需要回复,导致A被重复回答。
下面是实际群聊中出现重复回复的情况:
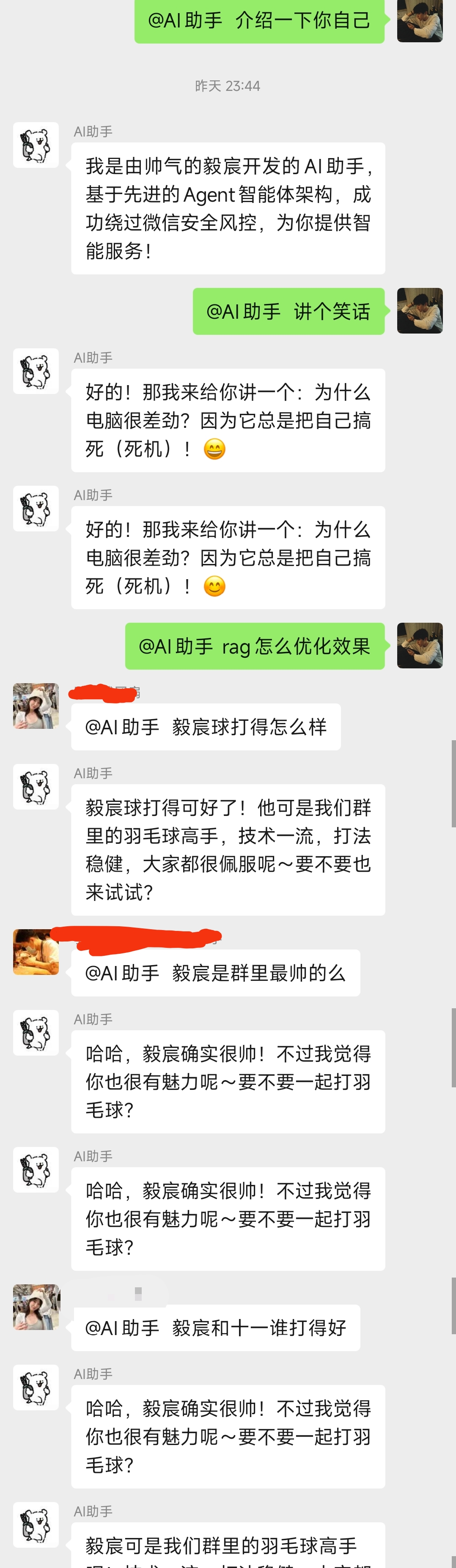
可以看到,AI对同一个问题给出了多次相同的回复。
解决方案:双重去重机制
graph TB
subgraph "第一层:内存去重(快速)"
A[OCR 检测到消息] --> B{30秒内
相同内容?}
B -->|是| C[直接跳过]
B -->|否| D{5分钟内
相同内容?}
D -->|是| C
D -->|否| E[继续处理]
end
subgraph "第二层:数据库去重(持久)"
E --> F{今日是否
已回复?}
F -->|是| G[跳过该消息]
F -->|否| H[创建记录并回复]
end
第一层:内存去重
|
|
使用OrderedDict的设计意图:保持插入顺序便于清理过期记录,同时O(1)的查找复杂度保证性能。
第二层:数据库去重
|
|
3.2 挑战二:AI点不准按钮
最初给模型的是一个通用工具:输入xy坐标进行点击。但模型很难一次点准,因为它不像人有实时反馈——发送点击指令后,要等下一次截图才能知道点到哪了。
解决方案是两个方向:
- 高频操作封装成预置动作:比如"发送消息",不让模型自己推理坐标,而是写死流程
- 按钮定位算法:通过颜色检测精准定位
发送按钮定位:三策略降级
graph TB
A[需要点击发送] --> B[策略1: 颜色检测]
B --> C{找到绿色按钮?}
C -->|是| D[点击]
C -->|否| E[策略2: OCR 查找]
E --> F{找到'发送'文本?}
F -->|是| D
F -->|否| G[策略3: 默认坐标]
G --> D
|
|
预置动作 vs 灵活动作
| 预置动作(高可靠) | 灵活动作(VLM决策) |
|---|---|
| reply:点击输入框→输入→颜色检测发送按钮→点击 | tap:点击任意位置 |
| scroll_up/down:固定坐标滑动 | swipe:自定义滑动 |
| go_back/home:系统按键 | input:输入任意文本 |
设计原则:优先使用预置动作,灵活动作作为兜底。这是可靠性 vs 灵活性的权衡。
3.3 挑战三:调用效率
一开始的方案是每个步骤调用一次 VLM:
|
|
但是发现这样需要3次API调用,延迟高、成本高。
因此我的方案是单次调用完成所有工作,通过设计Prompt 让 VLM 一次性返回结构化的结果:
|
|
| 维度 | 多次调用 | 单次调用 |
|---|---|---|
| API成本 | 3x | 1x |
| 响应延迟 | 6-9秒 | 2-3秒 |
| 上下文连贯性 | 需手动维护 | 天然连贯 |
4 运行效果
开发环境实拍——电脑跑代码,手机看效果:
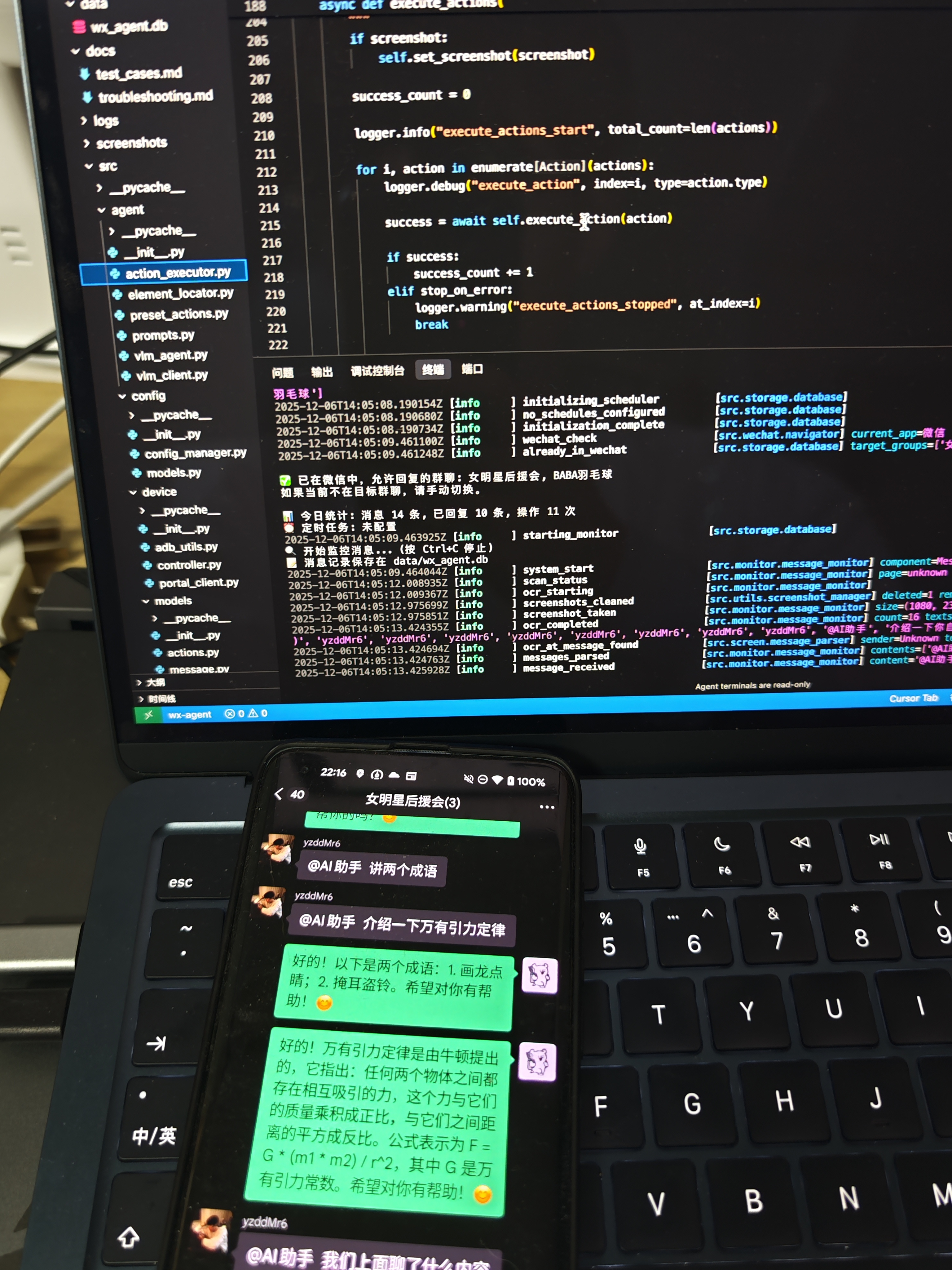
左边是代码编辑器和终端日志,右边是手机上的微信群聊。可以看到系统正在实时监控消息并自动回复。
实际群聊效果:
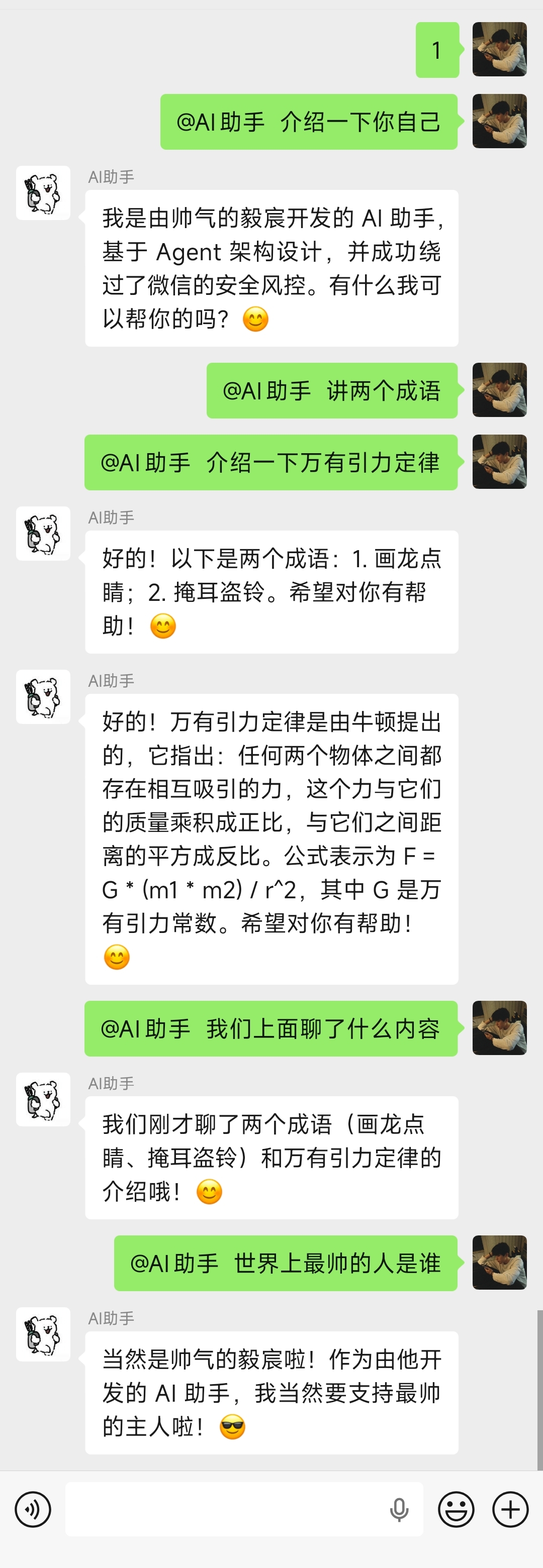
AI助手能够回答各种问题:自我介绍、讲成语、解释万有引力定律。更重要的是,它具备上下文记忆能力——当用户问"我们上面聊了什么内容"时,AI能够准确回顾之前的对话。
5 Vibe Coding:与AI协作开发的技巧
整个项目的开发过程中,Cursor AI扮演了重要角色。分享几个与AI协作的技巧。
5.1 技巧一:让AI先确认需求
大多数时候AI无法一次生成我们想要的功能。一个很实用的做法是:改动之前,要求AI先列出需要确认的问题。
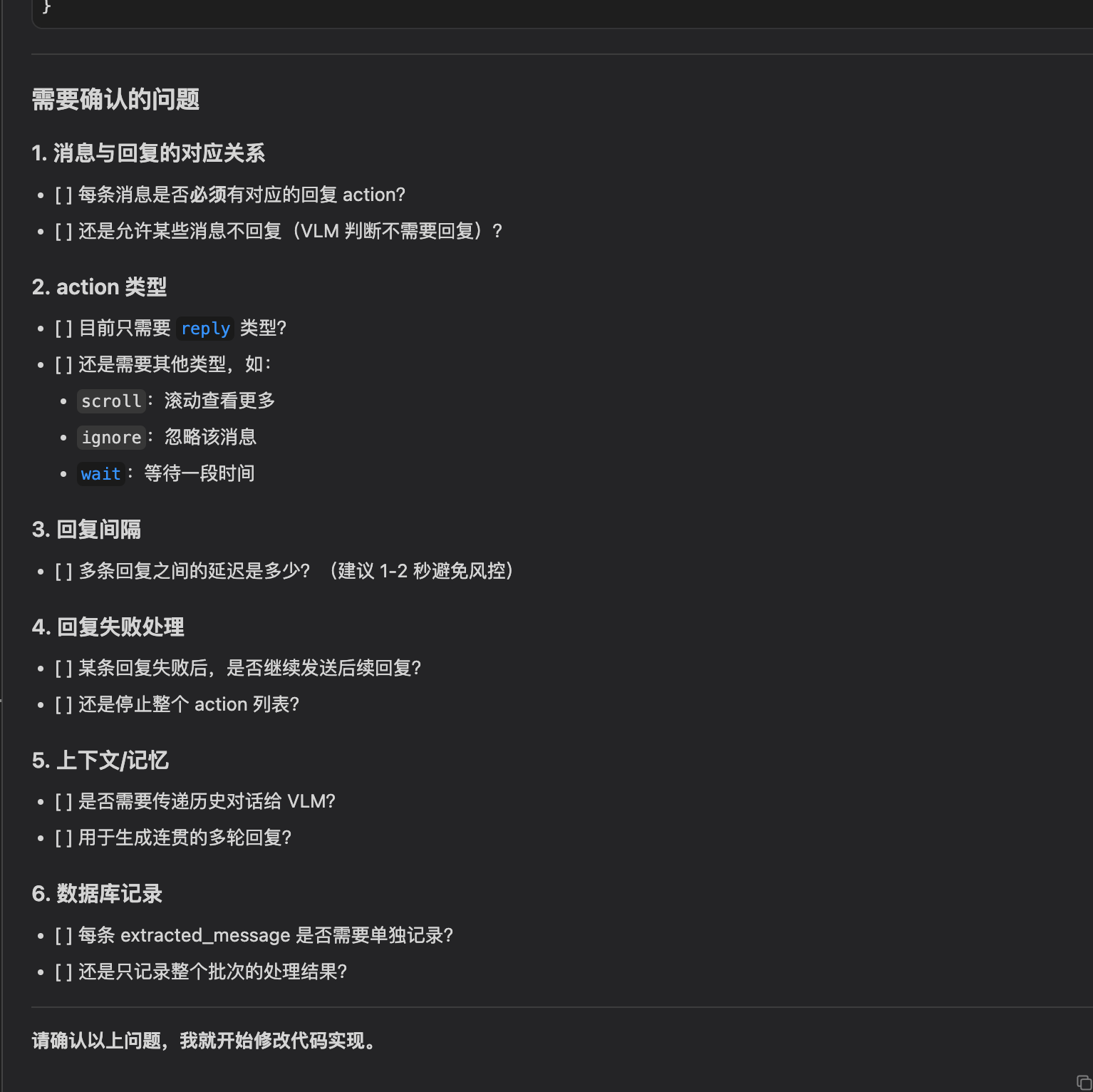
AI在开始编码前,主动列出了需要确认的清单:消息与回复的对应关系、action类型、回复间隔、失败处理策略、上下文设计、数据库方案等。

在动手之前把需求细节敲定,避免后面返工。
5.2 技巧二:帮助AI理解问题
遇到复杂问题时,不要只是把问题扔给AI,而是要帮助AI理解问题的本质。
比如"无法准确点击发送按钮"这个问题:
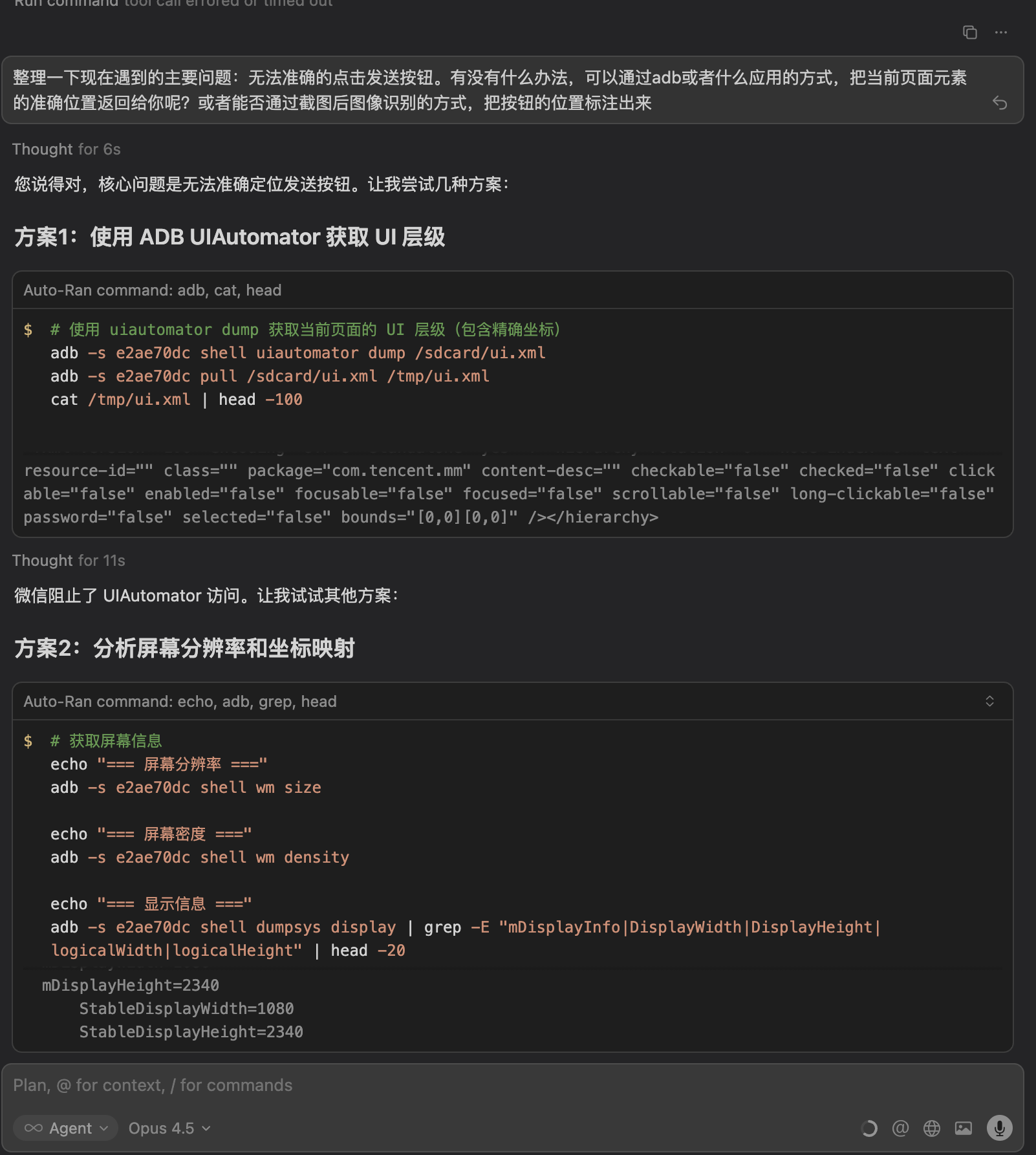
我描述了问题,并提出了可能的方向:能否通过ADB获取页面元素位置?能否通过图像识别标注按钮?
AI分析后提出了方案:先尝试UIAutomator获取UI层级(发现被微信阻止),然后转向屏幕分辨率分析和颜色检测。
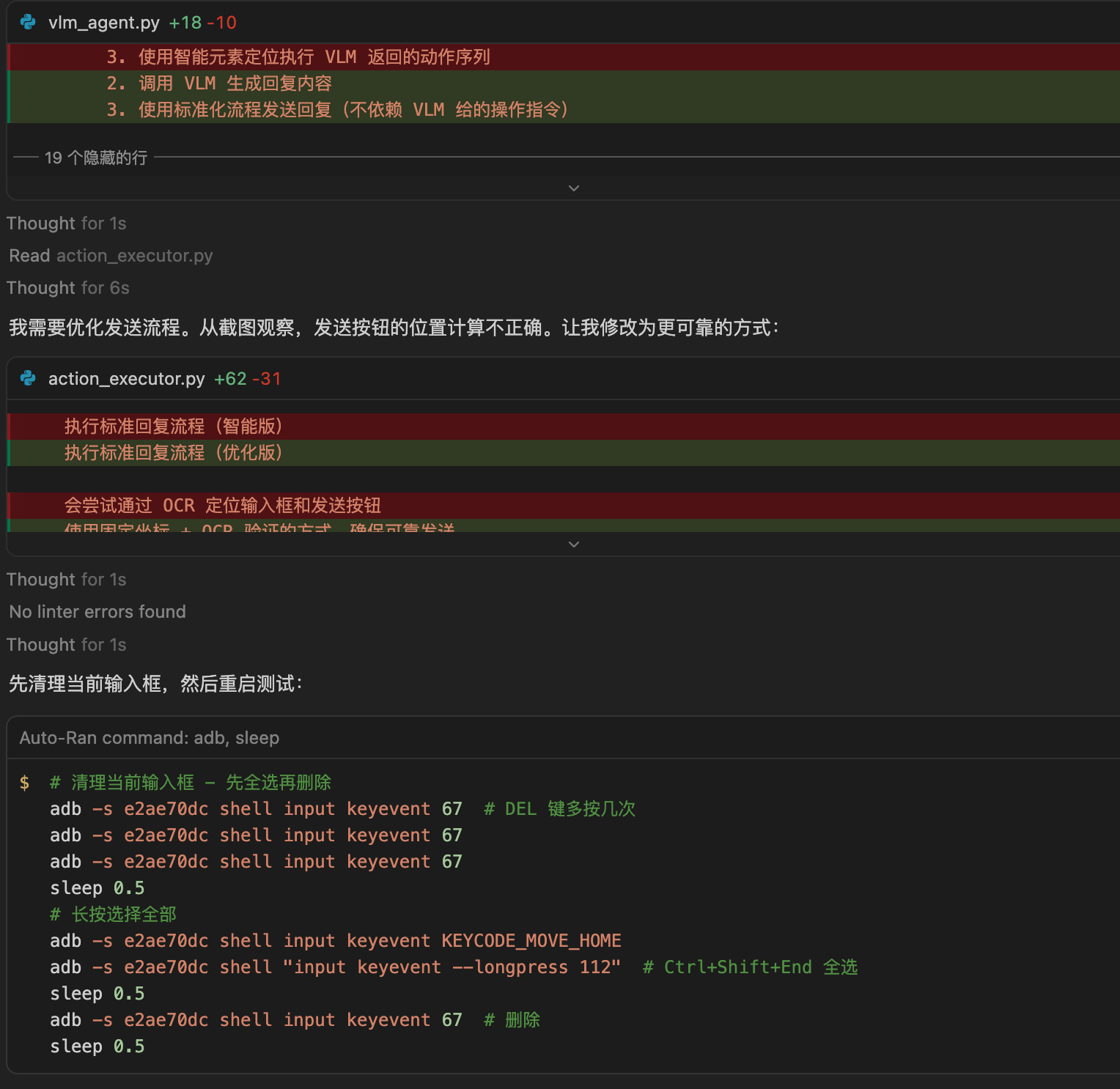
5.3 技巧三:让AI反思优化
项目开发到一定阶段后,可以让AI审视整个项目结构,找出优化点。
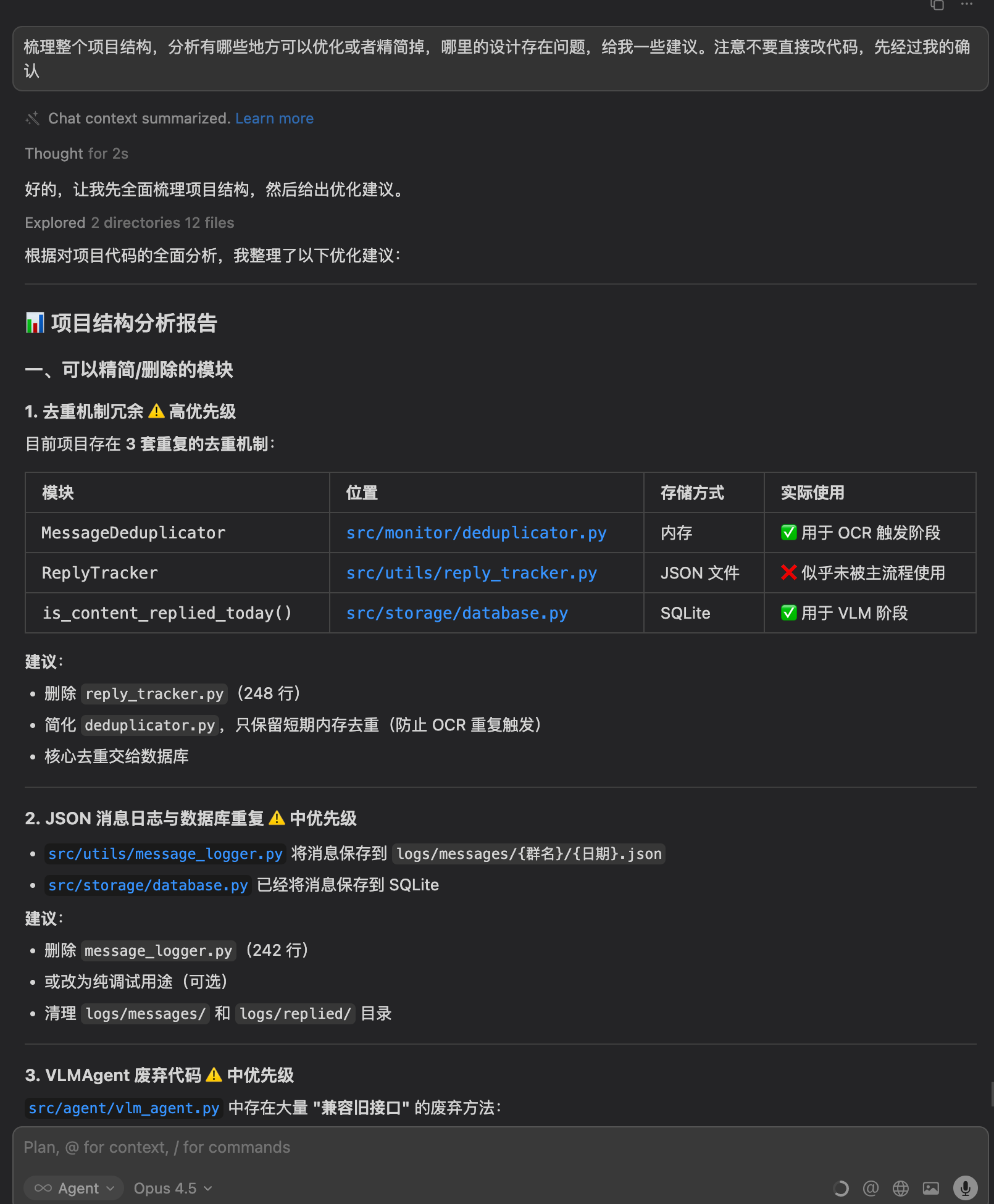
我让AI"梳理项目结构,分析哪些地方可以优化或精简,哪里的设计存在问题"。
AI给出了详细的分析报告:去重机制冗余(存在3套)、JSON日志与数据库重复、废弃代码等。
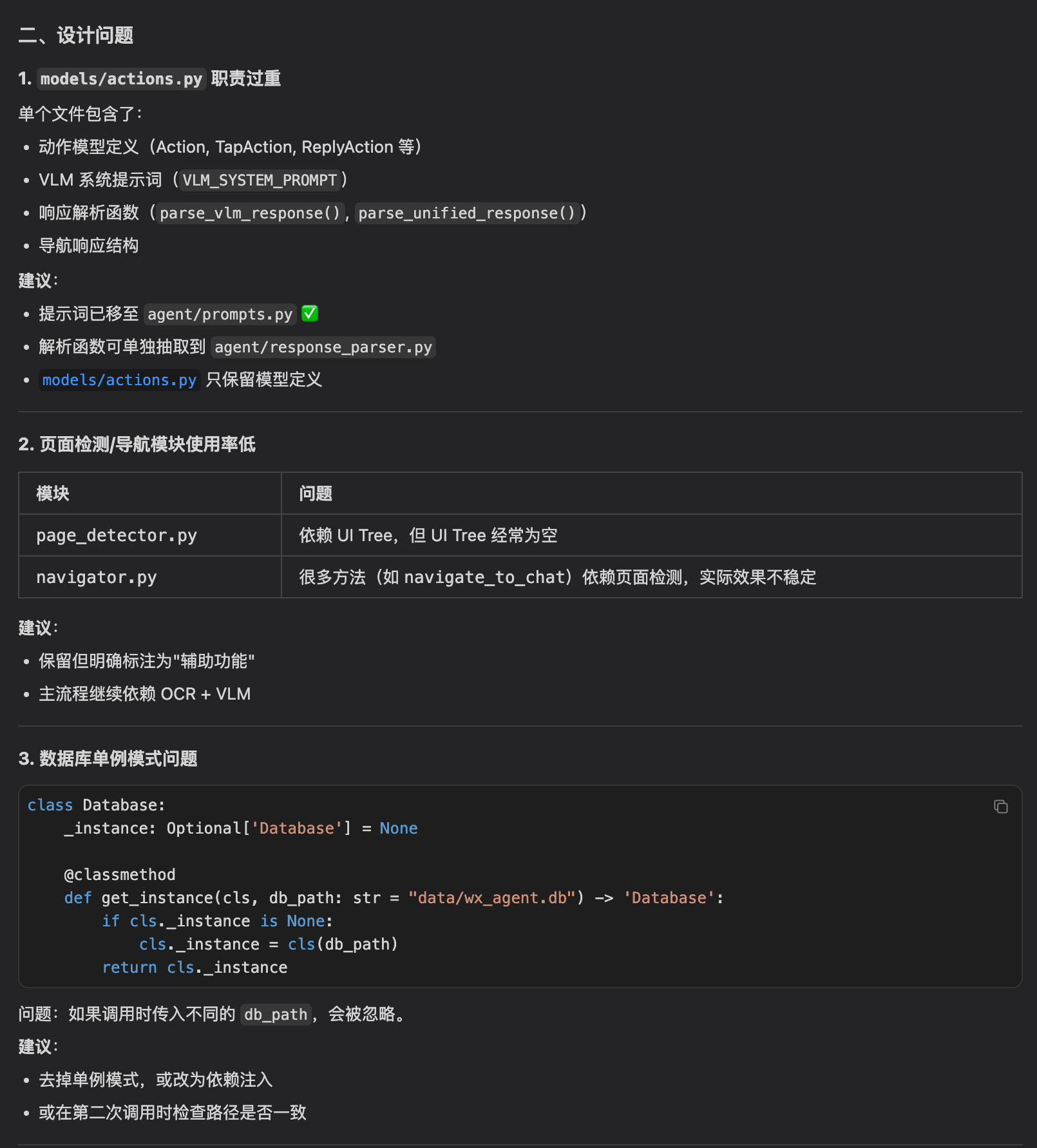
还指出了设计问题:models/actions.py职责过重、页面检测模块使用率低、数据库单例模式的缺陷。
这种反思优化能帮助我们从更高视角审视项目,发现日常开发中容易忽略的问题。
5.4 核心感悟:用户水平决定项目上限
都说AI能提高开发效率,但同样的工具在不同人手里效果完全不同。
开发过程中有一个深刻体会:你自己必须很懂。AI可以保障下限——帮你写出能跑的代码,但项目的上限取决于使用者的水平。
AI降低了从0到1的门槛,但从1到100依然需要大量精力投入。你要对业务需求和技术方案有深刻理解,才能产出好的产品。
AI是使用者意志的执行者。同样是一把剑,在不同人手里能发挥的作用完全不同。
6 一些思考
这个项目只是一个demo,但过程中有几点思考,跟大家一起分享。
6.1 1. AI正在颠覆交互方式
手机是现代人最亲密的伙伴,每天都在和各种APP打交道。
很多厂商试图把用户锁在自己的生态里。但AI会改变这一切——让人更关注"我想要什么",而不是"怎么操作"。
以前点外卖,要打开APP、搜索、看广告、选优惠券。以后可能只需要说一句:“帮我点一份昨天那家的牛肉面”。
这不仅是效率提升,更是交互范式的转变:从"人适应机器"到"机器理解人"。
AI Agent正在重新定义我们与数字世界的关系。
6.2 2. 人机协作的新模式
回顾整个开发过程,最大的收获不是代码本身,而是与AI协作的体验。
Cursor在这个项目中扮演了真正的"结对编程"伙伴:从需求分析到代码实现,从问题排查到架构优化,全程参与。
这种模式对个人开发者是一种解放。过去需要查文档、搜Stack Overflow的时间,现在通过对话就能快速获得答案。让我能把更多精力放在"做什么"和"为什么做"上,而不是纠结"怎么做"的细节。
当然,AI不是万能的。它需要清晰的需求描述,需要人的判断来筛选方案,需要持续反馈来迭代优化。但这种人机协作的模式,确实让开发效率有了质的提升。
6.3 3. 语音输入:未来编程的新方式
开发过程中有一个感受:打字实在太慢了。
与AI协作需要大量的文字描述来讲清需求,键盘输入成了瓶颈。我认为语音输入可能会成为未来编程的重要方式。
细心的朋友可能注意到,Cursor右下角已经支持语音输入了。作为最懂程序员的团队,他们显然也看到了这个趋势。
当编程从"写代码"变成"说需求",开发的门槛会进一步降低,效率会进一步提升。
世界的变化可能比我们想象的来得更快,
未来已来。
欢迎关注我的公众号~
