刷buuoj的时候遇到[安洵杯 2019]easy_web 这样一个题,做一半看到他这个正则写的有点问题,就去翻wp。
找到了官方的wp发现果然是个非预期。

但是官方wp中并没有深入说明。后来看到评论去翻出题人的博客也没找到相关的信息,加上看到了其他wp中一些不准确的说法,所以今天就有了这篇文章来讲一讲自己的看法。
题目源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
<?php
error_reporting(E_ALL || ~ E_NOTICE);
header('content-type:text/html;charset=utf-8');
$cmd = $_GET['cmd'];
if (!isset($_GET['img']) || !isset($_GET['cmd']))
header('Refresh:0;url=./index.php?img=TXpVek5UTTFNbVUzTURabE5qYz0&cmd=');
$file = hex2bin(base64_decode(base64_decode($_GET['img'])));
$file = preg_replace("/[^a-zA-Z0-9.]+/", "", $file);
if (preg_match("/flag/i", $file)) {
echo '<img src ="./ctf3.jpeg">';
die("xixi~ no flag");
} else {
$txt = base64_encode(file_get_contents($file));
echo "<img src='data:image/gif;base64," . $txt . "'></img>";
echo "<br>";
}
echo $cmd;
echo "<br>";
if (preg_match("/ls|bash|tac|nl|more|less|head|wget|tail|vi|cat|od|grep|sed|bzmore|bzless|pcre|paste|diff|file|echo|sh|\'|\"|\`|;|,|\*|\?|\\|\\\\|\n|\t|\r|\xA0|\{|\}|\(|\)|\&[^\d]|@|\||\\$|\[|\]|{|}|\(|\)|-|<|>/i", $cmd)) {
echo("forbid ~");
echo "<br>";
} else {
if ((string)$_POST['a'] !== (string)$_POST['b'] && md5($_POST['a']) === md5($_POST['b'])) {
echo `$cmd`;
} else {
echo ("md5 is funny ~");
}
}
|
前面md5碰撞已经是老套路了,问题出在后面对shell命令的过滤上。
1
2
3
4
|
if (preg_match("/ls|bash|tac|nl|more|less|head|wget|tail|vi|cat|od|grep|sed|bzmore|bzless|pcre|paste|diff|file|echo|sh|\'|\"|\`|;|,|\*|\?|\\|\\\\|\n|\t|\r|\xA0|\{|\}|\(|\)|\&[^\d]|@|\||\\$|\[|\]|{|}|\(|\)|-|<|>/i", $cmd)) {
echo("forbid ~");
echo "<br>";
}
|
熟悉php代码审计的同学应该都知道,在preg_match中要过滤\ 是需要四个\\\\才可以达到目的,原理如下:
1
2
3
4
5
6
7
8
9
10
11
12
|
$str = '\/div';
$pattern = '/\\\\\/div/';
// '\\\\\/' 解析过程如下:
// PHP解析:
// 第1个'\'转义第2个'\',转义后为字符串'\'
// 第3个'\'转义第4个'\',转义后为字符串'\'
// 第5个'\'转义'/',转义后为字符串'/'
// 字符合起来为'\\/' (则 \\/div 即为正则将要解析的内容,注意:正则解析的内容已经不包括正则标识符//)
// 正则解析器解析:
// 两个'\\' 正则表达式看做'\' (则正则最终解析为 \/div)
$rs = preg_match($pattern, $str, $arr);
if($rs) print_r($arr); // Array ( [0] => \/div )
|
但是出题人似乎觉得不够,又在后面加了四个反斜杠的匹配,似乎本意是要过滤\跟\\?
理论来说已经出现了四个\\\\了,但是为什么还会造成非预期ca\t这种解呢?
我们本地测试一下
去掉其他的乱七八糟的东西,只留下对于反斜杠等的过滤
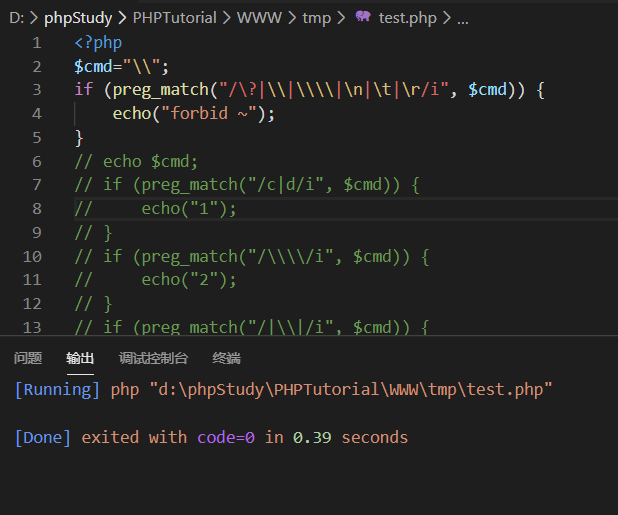
可以看到虽然正则中有\\\\,但是却无法过滤到反斜杠。
反向思考其原因,应该是问题出在前面两个反斜杠的匹配部分。
因为正则匹配中相当于要经过两层解析器解析,一层是php的,一层是正则表达式的。所以此处前面的两个反斜杠经过php解析器处理后应该是表示了一个转义号\,之后又与后面的表示逻辑或的|结合到一起,从而在正则表达式解析器中解析为\|。又因为|是正则中的保留符号,所以需要一个转义符来转义。所以最后的实现效果应为对于字符|的过滤。
所以我们猜测这种写法真正被解析的结果应该是对于字符串|\的过滤,即不是单独的\的匹配。
我们来验证一下猜想是否正确:
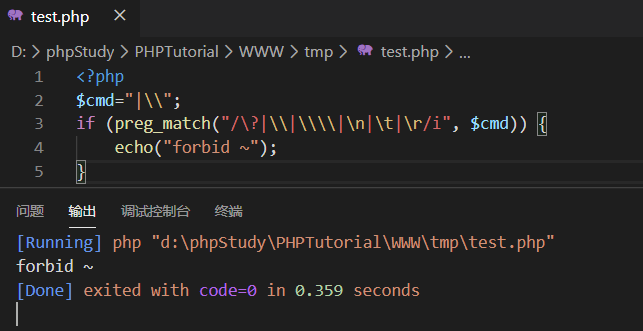
可以看到此时已经触发了正则匹配机制,输出了forbid。
所以综上所述:非预期的原因是错误的正则写法匹配了|\,而非预期的\
https://www.cnblogs.com/20175211lyz/p/12189515.html
这篇文章中提到反斜杠有这么多种匹配方法,如果你做实验的话发现也确实会输出1234。事实真的是这样吗?
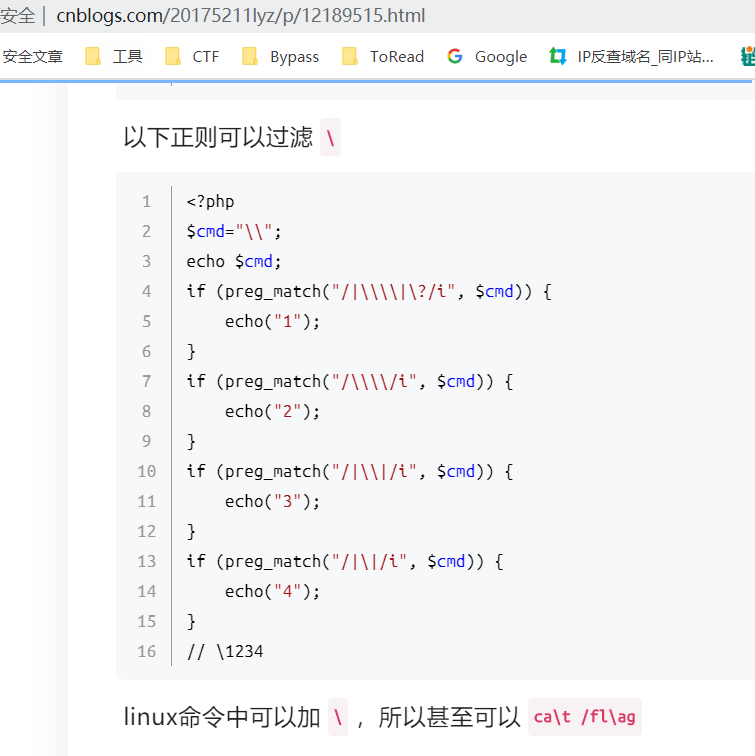
随便写个字符串,发现134照样可以匹配到。
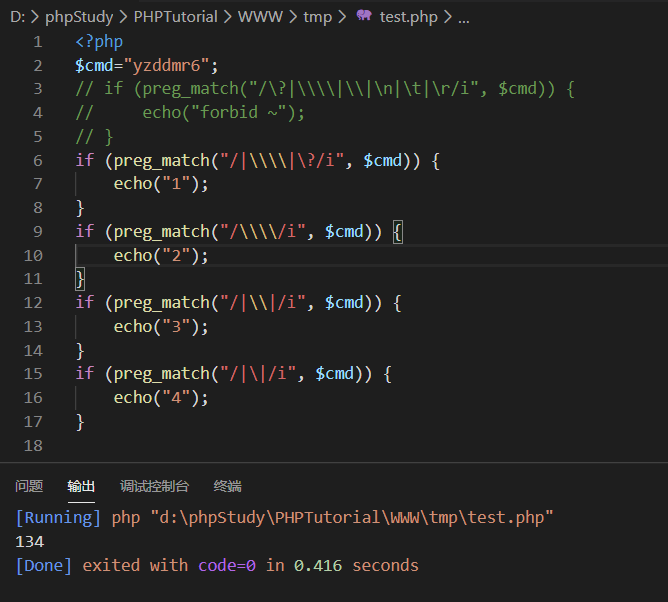
原因是134条规则都在左右多加了个|,然而|左右为空,也就是说对于任意空字符串都可以匹配,而并非预期的目的。
这篇文章的解释是把\t当成tab,这个就更离谱了。
https://blog.csdn.net/SopRomeo/article/details/104124545
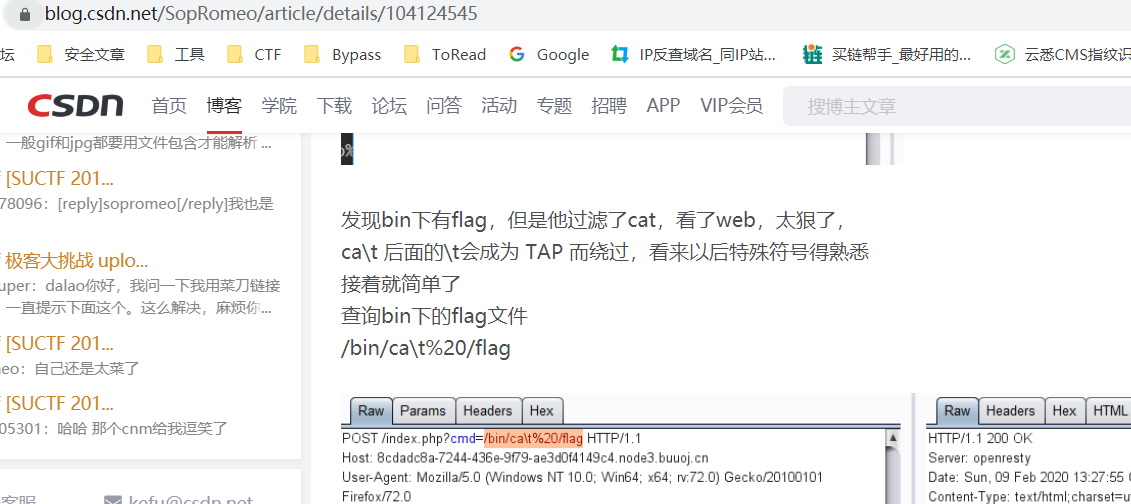
https://www.jianshu.com/p/21e3e1f74c08
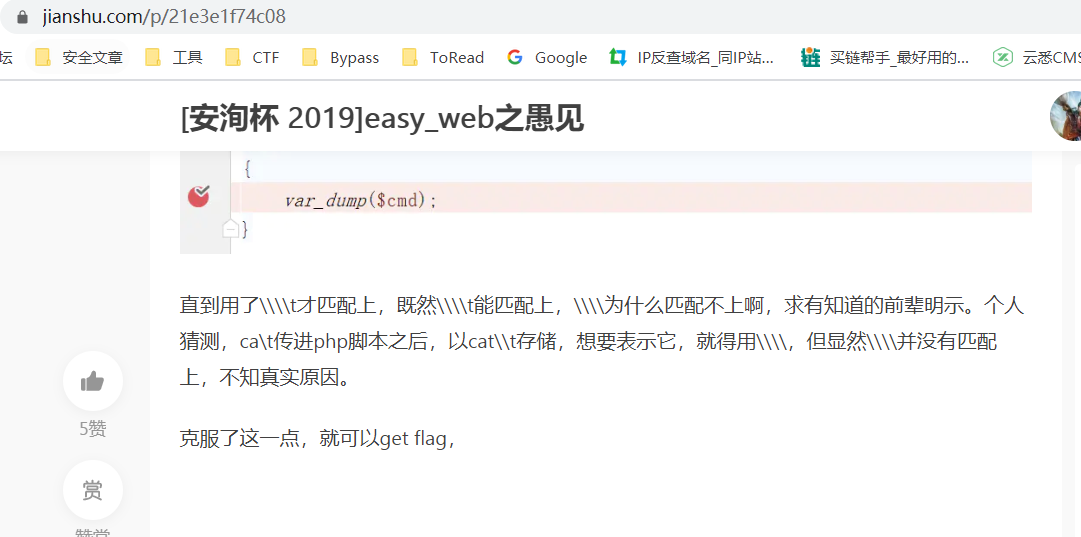
这个同学自己调试了一番,离真相就差一点啦。
纸上得来终觉浅,绝知此事要躬行。
与君共勉。
