万字长文:Oh My OpenCode 深度架构分析报告
分析版本:v3.7.4 | 分析日期:2026-02-20
代码规模:910 个源文件(68k 行实现 + 67k 行测试),256 个测试文件
技术栈:TypeScript + Bun + Zod + MCP SDK + OpenCode Plugin API
1 一、项目定位与核心价值
Oh My OpenCode(以下简称 OMO)是 OpenCode 的一个"超级插件"。OpenCode 本身是一个终端 AI 编程工具(类似 Claude Code),而 OMO 的定位是:把 OpenCode 从一个单 agent 工具,变成一个多 agent 编排平台。
用一句话概括:OMO 是 AI 编程工具的 “oh-my-zsh”——它不改变宿主的核心,但通过插件机制注入了一整套 agent 体系、工具链、自动化循环和智能降级策略,让 OpenCode 的能力提升了一个量级。
核心卖点:
- 多 agent 编排(Sisyphus 指挥、Oracle 顾问、Librarian 查资料、Explore 搜代码……)
- 后台并行 agent(通过 OpenCode session API + tmux 可视化)
- LSP/AST-grep 工具(给 AI 真正的代码理解能力,不只是文本搜索)
- Ralph Loop(自动续跑机制,agent 停了自动踢一脚继续干)
- Claude Code 兼容层(可以加载 Claude Code 的 agent、skill、MCP 配置)
- 多 provider 智能降级(Claude/OpenAI/Gemini/Copilot 自动切换)
2 二、整体架构
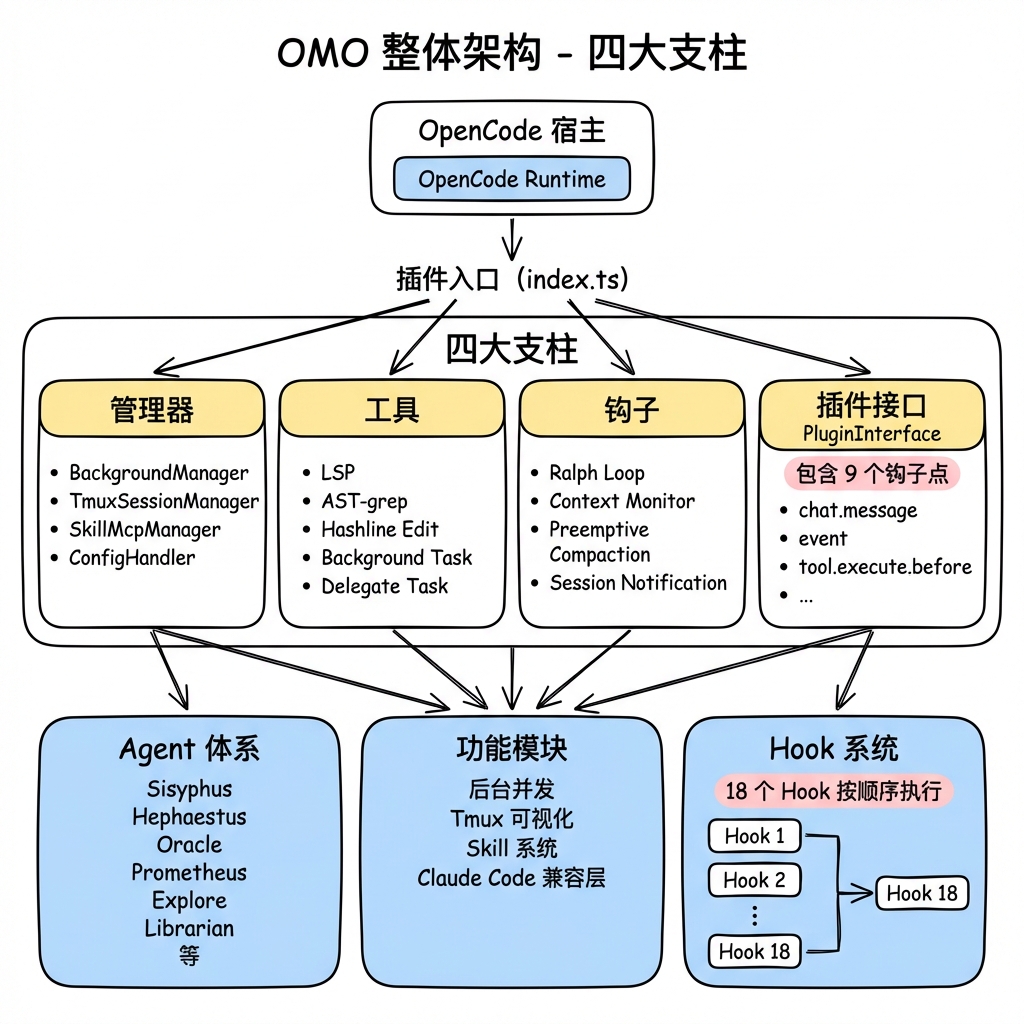
OMO 的架构可以用"四大支柱"来理解——插件入口 src/index.ts 依次创建四个核心组件:
- Managers(
create-managers.ts):管理后台 agent 并发、tmux 窗格、skill MCP 服务、配置处理 - Tools(
create-tools.ts):注册所有工具(LSP、AST-grep、background task、session manager 等) - Hooks(
create-hooks.ts):注册事件钩子(Ralph Loop、上下文监控、预压缩、通知等) - PluginInterface(
plugin-interface.ts):将以上三者组装成 OpenCode 期望的插件接口
这个分层非常清晰——每一层只依赖上一层的输出,职责边界明确。
2.1 ConfigHandler 6 步处理管线
PluginInterface 的核心是 createConfigHandler()(src/plugin-handlers/config-handler.ts),它按固定顺序调用 6 个子处理器:
|
|
这个顺序有严格的依赖关系——applyAgentConfig 的返回值 agentResult 被传给 applyToolConfig,因为工具权限需要知道哪些 agent 存在。
| 处理器 | 源文件 | 核心职责 |
|---|---|---|
| provider-config-handler | src/plugin-handlers/provider-config-handler.ts |
从 provider 配置提取模型上下文限制,检测 Anthropic context-1m beta,缓存 providerID/modelID → contextLimit 映射 |
| plugin-components-loader | src/plugin-handlers/plugin-components-loader.ts |
加载 Claude Code 插件生态的第三方插件,带 10 秒超时保护 |
| agent-config-handler | src/plugin-handlers/agent-config-handler.ts |
最复杂(226 行):迁移旧版 agent 名称 → 发现所有 skill 来源 → createBuiltinAgents() → 合并 user/project/plugin agents → remapAgentKeysToDisplayNames → reorderAgentsByPriority |
| tool-config-handler | src/plugin-handlers/tool-config-handler.ts |
禁用 OpenCode 原生冲突工具,为每个 agent 设置精细工具权限矩阵 |
| mcp-config-handler | src/plugin-handlers/mcp-config-handler.ts |
合并 builtin MCPs → 用户配置 → Claude Code MCPs → 插件 MCPs,尊重 enabled: false |
| command-config-handler | src/plugin-handlers/command-config-handler.ts |
14 级优先级命令合并(builtinCommands → … → pluginComponents.skills) |
辅助模块:category-config-resolver.ts(解析 category 配置)、prometheus-agent-config-builder.ts(构建 Prometheus 完整配置)、agent-priority-order.ts(确保核心 agent UI 排序)、agent-key-remapper.ts(内部 key → 显示名映射)。
2.2 PluginInterface 暴露的 9 个钩子点
createPluginInterface()(src/plugin-interface.ts)返回的对象包含以下钩子,构成了 OMO 与 OpenCode 宿主的全部交互面:
| 钩子名 | 职责 |
|---|---|
tool |
注册自定义工具 |
chat.params |
拦截/修改聊天参数(temperature、topP 等) |
chat.headers |
注入 HTTP 请求头(如 GitHub Copilot 的 x-initiator: agent) |
chat.message |
拦截/修改用户消息(最复杂的拦截器) |
experimental.chat.messages.transform |
变换消息历史(Context Injector + Thinking Block 验证) |
config |
配置处理(上述 6 步管线) |
event |
事件分发(session 生命周期、idle 检测等) |
tool.execute.before |
工具执行前拦截(task 路由、ralph-loop 解析) |
tool.execute.after |
工具执行后拦截(输出截断、上下文监控) |
这是一个典型的中间件/拦截器模式。OMO 不直接实现 AI 对话逻辑,而是通过 OpenCode 提供的各个生命周期钩子点注入自己的逻辑。整个插件本质上是一个巨大的"拦截器集合"。
PluginInterface 的类型定义(src/plugin/types.ts)做了一个精妙的操作:从标准 PluginInstance 中移除 experimental.session.compacting 和 chat.headers,然后用自定义的 ChatHeadersHook 类型重新定义 chat.headers,以实现更精细的输入/输出签名控制。
3 三、Agent 体系:希腊神话式的多 agent 编排
这是 OMO 最核心的创新。它设计了一套以希腊神话命名的 agent 体系,每个 agent 有明确的职责、工具权限和模型匹配策略。核心设计理念是:不同的认知任务需要不同的模型能力和工具权限。
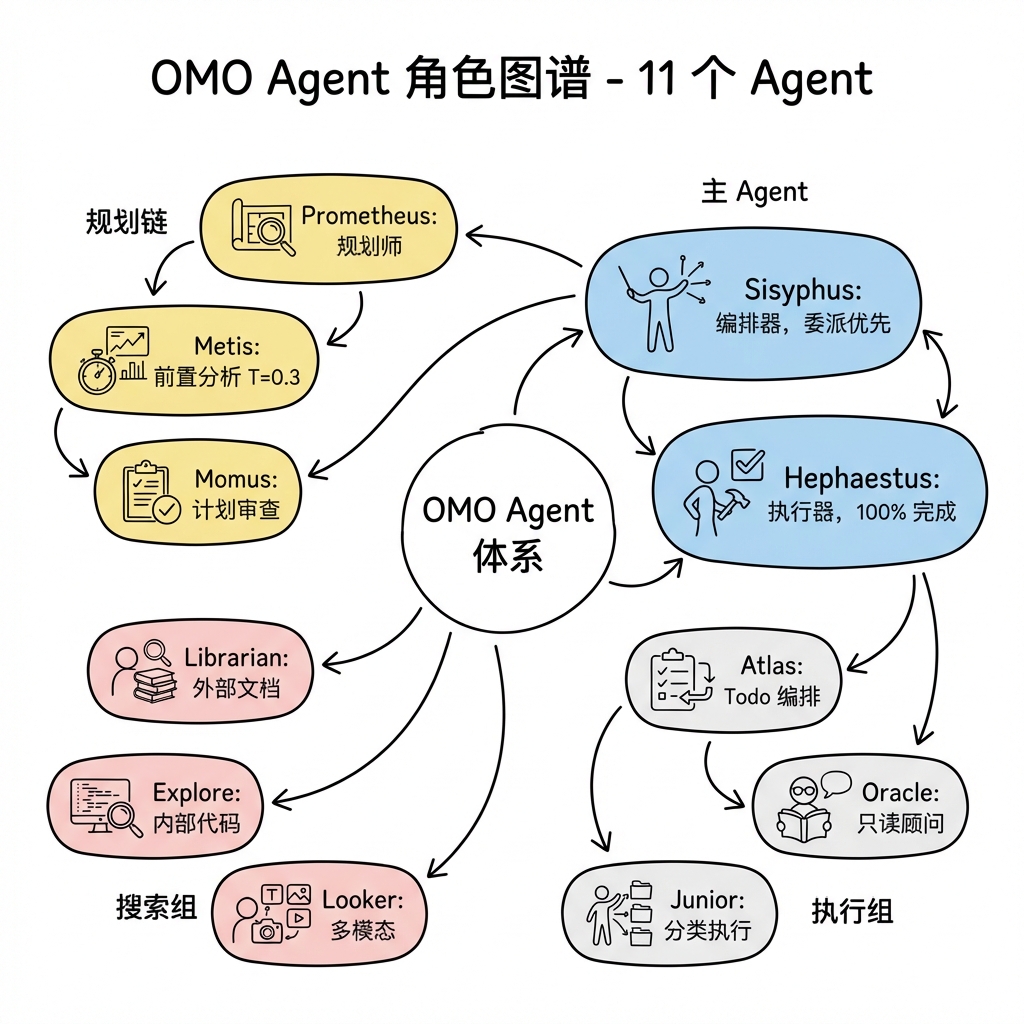
3.1 3.1 Agent 角色清单与协作拓扑
| Agent | 默认模型 | 温度 | 模式 | 核心职责 |
|---|---|---|---|---|
| Sisyphus | claude-opus-4-6 | 0.1 | primary | 主编排器,接收用户请求后进行意图分类、委派任务、验证结果 |
| Hephaestus | gpt-5.3-codex | 0.1 | primary | 自主深度执行器,端到端完成复杂任务,不中途停下 |
| Prometheus | claude-opus-4-6 | 0.1 | — | 战略规划师,只做计划不写代码,输出 .sisyphus/plans/*.md |
| Atlas | claude-sonnet-4-6 | 0.1 | primary | Todo 列表编排器,按波次并行调度任务执行 |
| Oracle | gpt-5.2 | 0.1 | subagent | 只读高智商顾问,用于架构决策和疑难调试 |
| Metis | claude-opus-4-6 | 0.3 | subagent | 规划前顾问,在 Prometheus 生成计划前做 gap 分析 |
| Momus | gpt-5.2 | 0.1 | subagent | 计划审查员,验证计划的可执行性和引用正确性 |
| Librarian | glm-4.7 | 0.1 | subagent | 外部文档/代码搜索,克隆仓库、查官方文档、搜 GitHub |
| Explore | grok-code-fast-1 | 0.1 | subagent | 内部代码库搜索,回答"X 在哪里"类问题 |
| Multimodal Looker | gemini-3-flash | 0.1 | subagent | 多模态文件分析,处理 PDF/图片/图表 |
| Sisyphus-Junior | claude-sonnet-4-6 | 0.1 | all | 分类任务执行器,由 category 系统派生,不能再委派 task() |
温度差异值得注意:大多数 agent 使用 temperature: 0.1(确定性输出),但 Metis 使用 0.3——作为"前置分析师"需要更多创造性来发现潜在问题和盲点。
协作拓扑形成了清晰的分层结构:
|
|
为什么用希腊神话命名?每个名字都暗示了 agent 的性格:Sisyphus 永不放弃地推石头(持续执行),Oracle 是神谕(只给建议不动手),Prometheus 是先知(规划未来)。这种命名让用户不需要读文档就能直觉理解每个 agent 的角色。
3.2 3.2 AgentPromptMetadata 自描述系统
每个 agent 通过 AgentPromptMetadata(src/agents/types.ts:43-67)声明式描述自己的能力边界:
|
|
dynamic-agent-prompt-builder.ts 提供一组 builder 函数,在构建 Sisyphus/Hephaestus prompt 时自动聚合所有 agent 的元数据:
buildKeyTriggersSection()— 从各 agent 的keyTrigger生成 Phase 0 触发器buildToolSelectionTable()— 生成工具和 agent 的成本选择表buildDelegationTable()— 从各 agent 的triggers生成委派决策表buildExploreSection()/buildLibrarianSection()— 生成搜索 agent 的使用指南buildOracleSection()— 生成 Oracle 使用规范buildCategorySkillsDelegationGuide()— 生成 category + skill 的委派协议buildHardBlocksSection()/buildAntiPatternsSection()— 生成硬性约束
核心价值:添加或移除一个 agent 时,Sisyphus 的 prompt 自动更新。每个 agent 通过 AgentPromptMetadata 自描述自己的能力,Sisyphus 的 prompt 在构建时自动聚合这些信息,实现了真正的"开放-封闭原则"。
包括第三方插件注册的 agent 也能自动融入——custom-agent-summaries.ts 的 parseRegisteredAgentSummaries() 解析外部 agent,buildCustomAgentMetadata() 为它们生成标准元数据(默认 category: "specialist", cost: "CHEAP"),添加到 availableAgents 列表后自动出现在 Sisyphus 的委派表和工具选择表中。
3.3 3.3 Sisyphus vs Hephaestus:双轨主 Agent 哲学
Sisyphus 和 Hephaestus 是两种截然不同的"主 agent"哲学,对应两种不同的用户工作风格——有人喜欢快速委派,有人喜欢深度自主。

Sisyphus——编排者(src/agents/sisyphus.ts:141-509,约 500 行 prompt)的核心理念:
- 分阶段决策流水线:Phase 0 (Intent Gate) → Phase 1 (Codebase Assessment) → Phase 2A/2B/2C → Phase 3 (Completion)。Phase 0 的意图分类(Trivial/Explicit/Exploratory/Open-ended/Ambiguous)决定后续走哪条路径,避免"一刀切"的处理方式。
- 委派优先,自己动手是最后选择:prompt 反复强调先检查有没有合适的 agent,再检查 category+skill 组合,最后才考虑自己做。这是一个"管理者"而非"执行者"的定位。
- 并行是默认行为:Explore 和 Librarian 被定义为"后台 grep",必须用
run_in_background=true启动,且必须并行发射 2-5 个。prompt 中甚至给出了详细的 prompt 模板(CONTEXT/GOAL/DOWNSTREAM/REQUEST 四段式),确保委派质量。 - Oracle 的特殊地位:唯一一个"永远不能取消"的 agent。prompt 中用大量篇幅强调:即使你觉得已经有了答案,也必须等 Oracle 返回结果。这反映了一个设计哲学——高质量推理的价值在你认为不需要它的时候最高。
- 证据驱动的完成标准:File edit → lsp_diagnostics clean on changed files;Build command → Exit code 0;Test run → Pass;Delegation → Agent result received and verified。NO EVIDENCE = NOT COMPLETE。
Hephaestus——自主执行者(src/agents/hephaestus.ts:106-499)与 Sisyphus 共享大量基础设施(都使用 dynamic-agent-prompt-builder 的 builder 函数),但在行为指令上有根本性差异。
核心差异:禁止询问,只管做
|
|
Intent Extraction 机制(src/agents/hephaestus.ts:176-203):Hephaestus 要求 agent 在处理每条消息时先提取"真实意图":
| 表面形式 | 真实意图 | 响应 |
|---|---|---|
| “Did you do X?” | 你忘了 X,现在做 | 承认 → 立即做 |
| “How does X work?” | 理解 X 以便修改 | 探索 → 实现/修复 |
| “What’s the best way?” | 用最好的方式做 | 决定 → 实现 |
设计灵感来自 AmpCode 的 deep mode(代码注释中明确提到),目标是让 agent 像一个"不需要管理的高级工程师"一样工作。
<turn_end_self_check> 自我约束(src/agents/hephaestus.ts:468-477):Hephaestus 的 prompt 末尾要求 agent 在结束每个 turn 前做四项检查,任何一项失败就不能结束 turn。这是一种"自我约束"的 prompt 工程技巧,确保 100% 完成。
3.4 3.4 Prometheus 三段式质量链
Prometheus 的 prompt 模块化程度最高,拆分为 6 个语义独立的文件:
| 文件 | 职责 |
|---|---|
identity-constraints.ts |
身份锁定(“YOU ARE A PLANNER. YOU ARE NOT AN IMPLEMENTER. YOU DO NOT WRITE CODE.") |
interview-mode.ts |
7 种意图类型的面谈策略(Trivial → Tiki-Taka 快速来回;Architecture → 必须咨询 Oracle) |
plan-generation.ts |
Metis 咨询 → gap 分类 → 摘要格式 |
high-accuracy-mode.ts |
Momus 审查循环 |
plan-template.ts |
计划文件 Markdown 模板 |
behavioral-summary.ts |
行为总结和最终约束 |
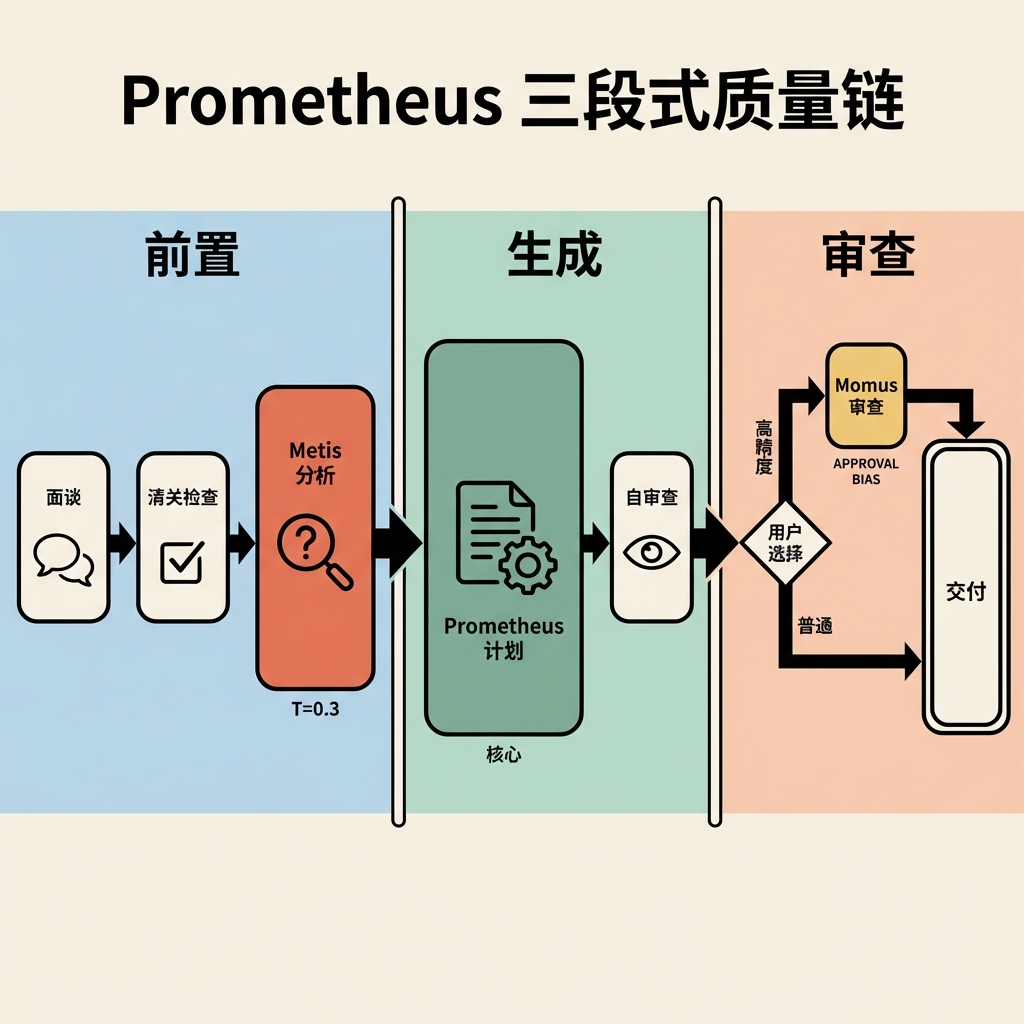
身份锁定是最核心的设计决策——即使用户说"just do it”,Prometheus 也必须拒绝并解释为什么需要规划。这种设计通过 prometheus-md-only hook 在系统层面强制执行——非 .md 文件的写入会被 hook 拦截。
三段式质量保证链:Metis(前置 gap 分析)→ Prometheus(计划生成)→ Momus(后置可执行性验证)。Momus 有明确的"APPROVAL BIAS"(默认通过),只拦截真正的 blocker,避免无限修改循环。
增量写入协议(identity-constraints.ts:163-228):大型计划会超出 LLM 的输出 token 限制,所以 prompt 要求先 Write 骨架,再用 Edit 分批追加任务(每批 2-4 个)。这是对 LLM 输出限制的显式适配。
3.5 3.5 构建、注册与权限控制
Agent 构建流程:所有 agent 遵循统一的工厂模式:
|
|
buildAgent()(src/agents/agent-builder.ts)是构建管线的核心,做三件事:
- 调用工厂函数:
source(model)生成基础配置 - 应用 category 配置:如果 agent 声明了
category,从用户配置中继承 model/temperature/variant - 注入 skill 内容:解析
skills数组,将 skill 内容前置拼接到 prompt(skill 指令优先级高于 agent 自身 prompt)
createBuiltinAgents()(src/agents/builtin-agents.ts:60)是整个 agent 系统的入口函数,执行顺序有严格依赖:
fetchAvailableModels()— 查询当前 provider 的可用模型collectPendingBuiltinAgents()— 收集除 Sisyphus/Hephaestus/Atlas 外的所有 agent,进行模型解析和配置构建parseRegisteredAgentSummaries()— 解析外部插件注册的 agent,为它们生成 metadatamaybeCreateSisyphusConfig()/maybeCreateHephaestusConfig()/maybeCreateAtlasConfig()— 最后构建主 agent
Sisyphus/Hephaestus/Atlas 必须最后构建,因为它们的动态 prompt 需要知道有哪些 subagent 可用。系统通过 isGptModel() 检测模型类型,对 GPT 模型使用 reasoningEffort: "medium" 而非 thinking: { type: "enabled", budgetTokens: 32000 }。Prometheus、Atlas、Sisyphus-Junior 都有完全独立的 GPT 优化 prompt(gpt.ts 文件)。
工具权限矩阵(src/shared/permission-compat.ts)通过 createAgentToolRestrictions() 和 createAgentToolAllowlist() 实现精细控制:
| Agent | 策略 | 被禁工具 | 设计意图 |
|---|---|---|---|
| Oracle | 黑名单 | write, edit, apply_patch, task | 只读顾问,防止"顾问自己动手" |
| Librarian / Explore | 黑名单 | write, edit, apply_patch, task, call_omo_agent | 只搜索不修改,不能派生子 agent |
| Multimodal Looker | 白名单 | 只允许 read | 最严格,只能读文件 |
| Metis / Momus | 黑名单 | write, edit, apply_patch, task | 只分析/审查不执行 |
| Atlas | 黑名单 | task, call_omo_agent | 可以读写文件,但不能再派生 agent |
| Sisyphus-Junior | 黑名单 | task(但允许 call_omo_agent) | 可调 explore/librarian,但不能用 task() 委派 |
微妙的设计:Sisyphus-Junior 允许 call_omo_agent 但禁止 task。这意味着它可以调用 explore/librarian 做搜索,但不能像 Sisyphus 那样通过 task() 委派工作给其他 category。这防止了无限递归委派。
全局权限设置(tool-config-handler.ts):webfetch=allow, external_directory=allow, task=deny(默认禁止 task,仅特定 agent 开放)。CLI 运行模式下禁用 question 工具(非交互环境)。
自定义 Agent 支持:parseRegisteredAgentSummaries() 解析外部插件注册的 agent,过滤掉 hidden、disabled、enabled: false 的条目,buildCustomAgentMetadata() 为它们生成标准元数据(默认 category: "specialist", cost: "CHEAP")。这意味着:安装一个新的 OpenCode 插件注册的 agent,Sisyphus 会自动知道它的存在并在合适的场景下委派任务给它。
4 四、工具体系
OMO 的工具体系分为三层:原生工具(src/tools/,直接与 AI agent 交互)、功能模块(src/features/,提供后台 agent、tmux、context injector 等复杂功能)、MCP 集成(src/mcp/,外部服务连接)。所有工具统一使用 @opencode-ai/plugin/tool 的 tool() 工厂函数定义,遵循相同的 (args, context) => Promise 接口。
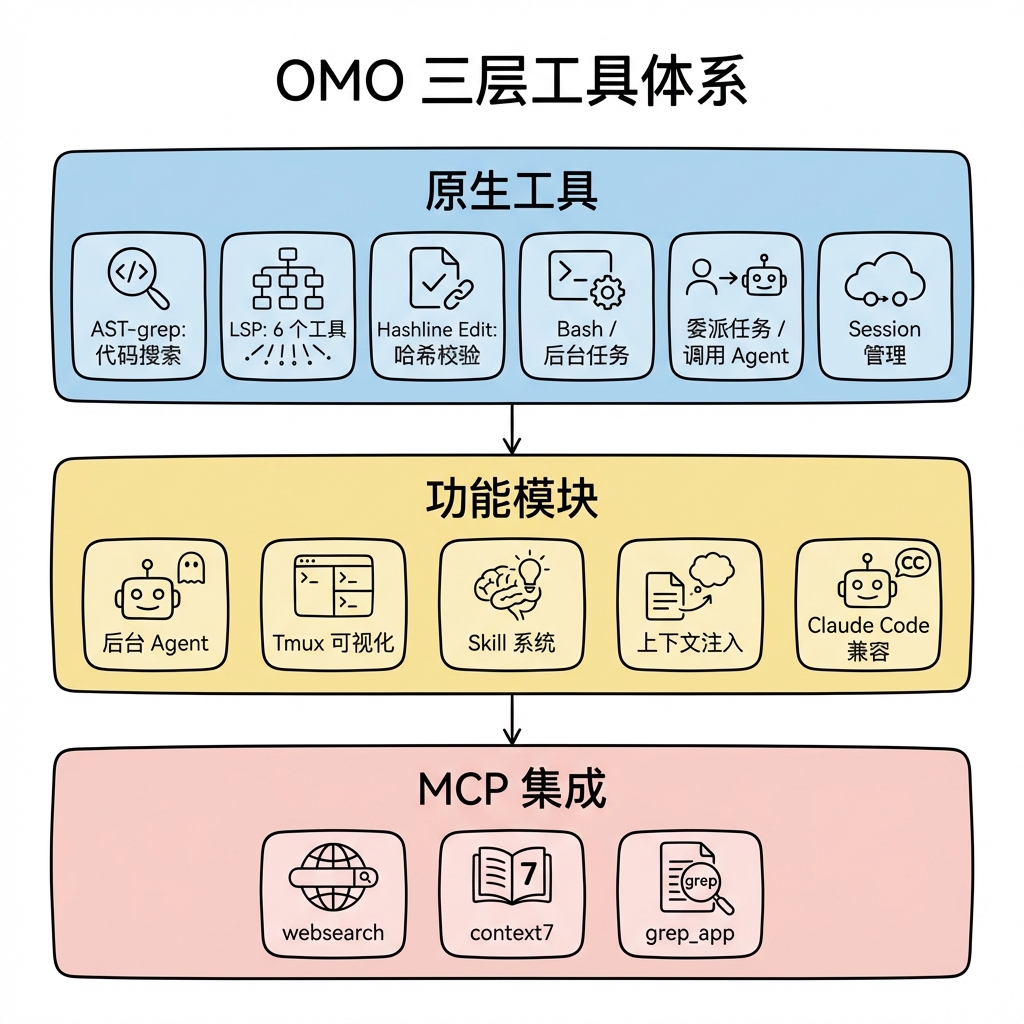
4.1 4.1 完整工具清单
| 工具目录 | 核心职责 | 关键设计 |
|---|---|---|
ast-grep/ |
AST 感知代码搜索/替换 | 25 语言,元变量 $VAR/$$$,空结果智能提示 |
lsp/ |
LSP 集成(6 个工具) | 4 层架构,双重诊断源(pull + push) |
hashline-edit/ |
行哈希精确编辑 | CID 哈希防幻觉,bottom-up 应用 |
interactive-bash/ |
tmux 命令执行 | 子命令黑名单,超时保护 |
background-task/ |
后台任务 CRUD | 创建/输出查看/取消 |
delegate-task/ |
任务委派中枢 | category 路由 + subagent 直接调用 |
call-omo-agent/ |
内置 agent 调用 | explore/librarian,同步/异步 |
look-at/ |
多模态文件分析 | 创建子 session 调用 multimodal-looker |
session-manager/ |
历史 session 操作 | list/read/search/info,60s 超时保护 |
skill/ + skill-mcp/ |
Skill 执行与 MCP 代理 | 加载 Skill 内容注入 prompt / 代理 MCP 调用 |
task/ |
任务 CRUD | create/get/list/update + todo-sync |
glob/ + grep/ |
文件搜索与内容搜索 | 内置 ripgrep 自动下载 |
工具注册入口在 src/tools/index.ts,LSP 的 6 个工具作为 builtinTools 静态导出,其余工具通过工厂函数按需创建。这种设计区分了"无状态工具"和"需要上下文的工具"。
4.2 4.2 Hashline Edit:防幻觉的精确编辑
src/tools/hashline-edit/ 是整个工具体系中最具创新性的设计,通过行级哈希防止 AI 编辑过时内容。
核心机制:每行内容生成 2 字符 CID 哈希(字符集 ZPMQVRWSNKTXJBYH),格式 LINE#ID(如 5#VK)。编辑操作必须携带正确的 LINE#ID 锚点,哈希不匹配则拒绝编辑并提示重新读取文件。4 种操作:set_line、replace_lines、insert_after、replace。编辑从底部向上应用(bottom-up),保持行号引用稳定。
解决的核心痛点:传统的精确文本匹配(如 Claude Code 的 Edit)在 AI 记忆不一致时会静默失败或错误编辑。Hashline Edit 将"文件是否过时"的检测前置到工具层,从根本上消除了基于过时内容编辑的问题。2 字符哈希在 token 开销和碰撞率之间取得了平衡——16^2 = 256 种组合,对于单个文件的行数来说碰撞概率极低。
4.3 4.3 LSP 与 AST-grep
LSP 4 层架构:
|
|
提供 6 个工具:
| 工具 | 功能 | LSP 方法 |
|---|---|---|
lsp_goto_definition |
跳转到定义 | textDocument/definition |
lsp_find_references |
查找引用 | textDocument/references |
lsp_symbols |
文档/工作区符号 | textDocument/documentSymbol, workspace/symbol |
lsp_diagnostics |
获取诊断信息 | textDocument/diagnostic + 推送诊断 |
lsp_prepare_rename |
重命名预检 | textDocument/prepareRename |
lsp_rename |
执行重命名 | textDocument/rename |
关键设计:
- 文档版本追踪:
documentVersionsMap 维护每个文件的版本号,确保didChange通知携带正确版本 - 内容去重:
lastSyncedTextMap 缓存上次同步文本,避免无变化时发送冗余通知 - 双重诊断源:先尝试 pull 模式(
textDocument/diagnostic),失败回退到 push 模式(diagnosticsStore) - 服务器自动管理:
server-config-loader.ts自动发现,server-installation.ts自动安装
这比纯文本 grep 强太多了——AI 可以精确地找到一个函数的所有调用者,而不是搜索字符串碰运气。
AST-grep 智能提示:基于 ast-grep 实现结构化代码搜索,与 LSP 互补——LSP 擅长精确的符号级操作,AST-grep 擅长模式匹配(如"找到所有 console.log 调用")。支持 25 语言、元变量模式($VAR 单节点、$$$ 多节点)、二进制自动下载。getEmptyResultHint() 在空结果时给出修正建议——AI agent 经常写出不完整的 AST 模式(如只写函数名不写参数),智能提示大幅降低了工具调用失败率。
4.4 4.4 delegate-task 任务委派中枢
createDelegateTask()(src/tools/delegate-task/tools.ts,220+ 行)是最复杂的工具,支持:
- category 路由:指定 category → 自动使用 Sisyphus-Junior agent + category 对应的模型配置
- subagent 直接调用:指定 subagent_type → 直接使用该 agent
- session 续写:通过 session_id 继续已有 session,保持完整上下文
- 同步/异步执行:
run_in_background=true返回 task_id,false等待结果 - Skill 注入:
load_skills参数加载 Skill 内容注入到 agent system prompt - 不稳定 agent 处理:
isUnstableAgent标记的 category 使用特殊执行路径
在 tool-execute-before.ts 中的 agent 路由逻辑:
|
|
resolveSessionAgent()(src/plugin/session-agent-resolver.ts)通过查询会话的消息历史,找到第一条包含 agent 信息的消息,从而确定该会话使用的 agent。
4.5 4.5 MCP 集成策略
三个内置 MCP 服务器(全部 remote HTTP/SSE 连接):
| MCP | 服务地址 | 用途 | 认证 |
|---|---|---|---|
| websearch | mcp.exa.ai(默认)/ mcp.tavily.com |
通用网络搜索 | API key |
| context7 | mcp.context7.com |
库文档查询 | 可选 API key |
| grep_app | mcp.grep.app |
跨开源仓库代码搜索 | 无需认证 |
三个 MCP 覆盖了 AI 编程助手的三个核心外部信息需求:最新信息(websearch)、API 用法(context7)、实现参考(grep_app)。createBuiltinMcps()(src/mcp/index.ts)统一注册,全部使用 remote MCP 避免本地进程管理复杂性,支持通过 disabled_mcps 配置禁用。
5 五、后台 Agent 并发模型
这是 OMO 的第二大创新——让 AI agent 能像人类开发者一样"开多个终端窗口并行干活"。由两个核心模块协作:src/features/background-agent/(逻辑层,负责并发控制、任务生命周期、完成检测)和 src/features/tmux-subagent/(可视化层,负责 tmux pane 管理、布局规划)。
5.1 架构时序图
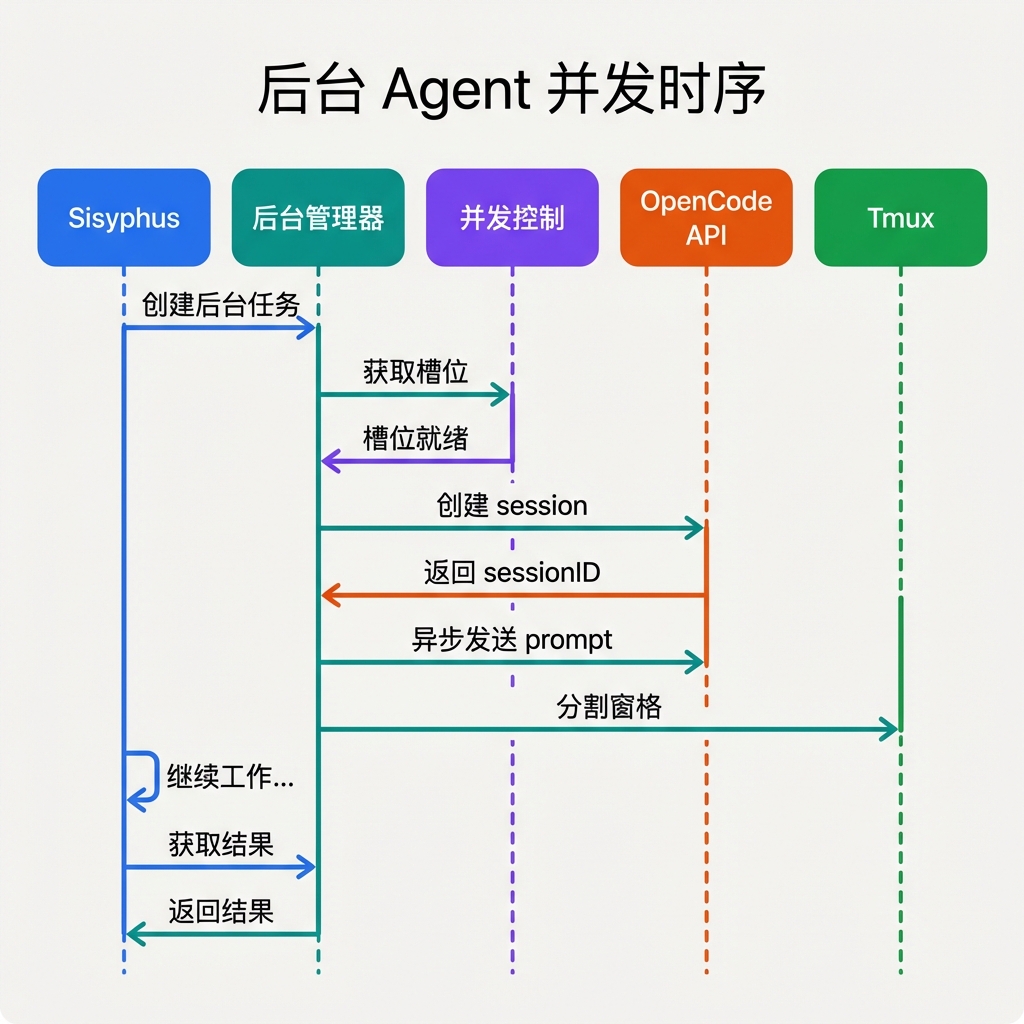
5.2 5.1 ConcurrencyManager:三级并发控制 + settled-flag
ConcurrencyManager(src/features/background-agent/concurrency.ts)实现三级粒度并发控制:
- 模型级限制:
modelConcurrency["anthropic/claude-sonnet-4-5"] = 3 - Provider 级限制:
providerConcurrency["anthropic"] = 5 - 全局默认:
defaultConcurrency = 5
查找顺序是 model → provider → default。不同模型的 rate limit 不同,Claude Haiku 可以开 10 个并发,Opus 可能只能开 2 个。
并发槽通过 Promise 队列实现等待:acquire() 在槽满时返回 pending Promise,release() 时将槽交给队列中的下一个等待者。
settled-flag 防 double-resolution(concurrency.ts:8-13):这是一个容易被忽略但很重要的细节——当 cancelWaiters() 和 release() 同时操作同一个 queue entry 时,没有这个 flag 就会出现 Promise 被 resolve 又被 reject 的问题。JavaScript 的单线程模型在大多数情况下保护了这一点,但 settled-flag 提供了额外的安全保障。
5.3 5.2 BackgroundManager 任务生命周期
BackgroundManager(src/features/background-agent/manager.ts)管理完整的任务生命周期(pending → running → completed/error/cancelled/interrupt)。核心设计:
-
Fire-and-Forget Prompt 模式:任务启动后,prompt 通过
promptWithModelSuggestionRetry()以 fire-and-forget 方式发送,不等待响应。错误通过.catch()异步处理,标记 interrupt、释放并发槽、abort session。 -
双重完成检测——两条路径互为备份:
- 事件驱动:监听
session.idle事件,经过MIN_IDLE_TIME_MS(5秒)最小运行时间校验 - 轮询兜底:
pollRunningTasks()定期检查所有 session 状态
- 事件驱动:监听
两条路径通过 tryCompleteTask() 汇聚,用状态检查实现原子性防止重复完成:
|
|
-
输出验证防止误完成:
validateSessionHasOutput()在标记完成前验证 session 确实有 assistant 输出(检查 text/reasoning/tool/tool_result 多种 part 类型),防止session.idle在 agent 还没响应时就触发完成。 -
批量通知机制:
pendingByParentMap 追踪每个父 session 的待完成任务。单个完成 → 静默通知(noReply: true);全部完成 → 汇总通知并触发父 session 响应。notificationQueueByParent确保同一父 session 的通知串行发送,避免消息乱序。 -
过期清理与僵尸防护:
pruneStaleTasksAndNotifications():30 分钟 TTL(TASK_TTL_MS)自动清理checkAndInterruptStaleTasks():检测无活动的 running 任务并中断- 进程退出时
shutdown()abort 所有 running session,registerProcessCleanup()注册 SIGINT/SIGTERM/beforeExit 信号处理
5.4 5.3 TmuxSessionManager 与两层协作
TmuxSessionManager(src/features/tmux-subagent/manager.ts)将后台 agent 映射到 tmux pane,实现可视化的并行执行。架构遵循 Query-Decide-Execute-Update 模式:
|
|
将 tmux 的实际状态作为唯一真实来源,内部 Map 仅作缓存,避免了状态不一致问题。纯函数 decideSpawnActions() 使决策逻辑可测试。
支持网格布局规划(grid-planning.ts 计算终端尺寸)、延迟队列(容量不足时 deferredSessions 等待空间释放后自动附加)、串行化 spawn(enqueueSpawn() 通过 Promise 链确保 spawn 操作串行执行,避免并发 tmux 操作导致的竞态)。三种 pane 操作:spawn(分割新 pane)、close(关闭已完成 pane)、replace(用新 session 替换旧 pane,避免频繁开关)。
BackgroundManager 和 TmuxSessionManager 通过回调连接:
|
|
BackgroundManager 创建 session 后通知 TmuxSessionManager 创建对应的 pane。200ms 延迟确保 tmux pane 在 prompt 发送前就绪。这让用户能在 tmux 里实时看到每个后台 agent 在干什么——不是黑盒,而是透明的。
为什么不用 Worker Threads?因为 OMO 不是自己运行 agent,而是通过 OpenCode 的 session API 创建新会话。每个后台 agent 就是一个独立的 OpenCode session,有自己的上下文和工具权限,完全复用了 OpenCode 的基础设施(模型调用、工具执行、权限管理)。
6 六、Ralph Loop 自动续跑
Ralph Loop 是 OMO 最有"性格"的功能——当 agent 完成一轮工作后,如果任务还没完成,自动注入 continuation prompt 让它继续干。名字来源于"像 Ralph 一样不知疲倦地工作"。核心思想:让 AI agent 在循环中反复执行,直到满足"完成承诺"(completion promise)或达到最大迭代次数。
6.1 状态机
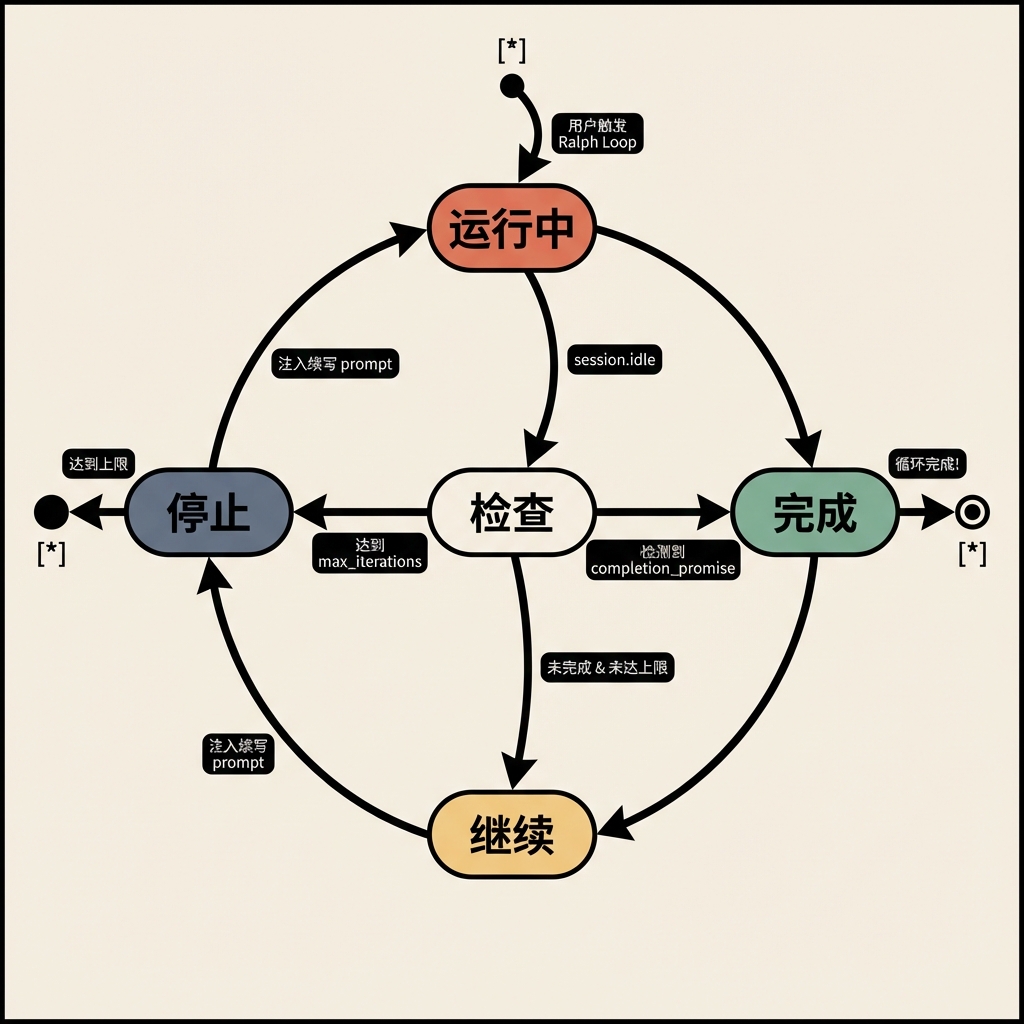
6.2 6.1 完整工作流
两条启动路径:
- Skill 命令路径:用户通过
/ralph-loop或/ulw-loop命令启动 →tool-execute-before拦截 skill 调用 → 解析参数(prompt、max-iterations、completion-promise) - 消息模板路径:
chat-message.ts检测消息文本是否包含 Ralph Loop 模板标记 → 解析<user-task>标签中的任务描述 → 提取--max-iterations和--completion-promise参数
启动后:
loopState.startLoop()创建循环状态并持久化到.sisyphus/ralph-loop.local.md- 当
session.idle事件触发时,ralph-loop-event-handler.ts检查:- 是否在恢复中(跳过)
- 是否检测到完成承诺(通过 transcript 文件或 session messages API)
- 是否达到最大迭代次数
- 如果未完成,递增迭代计数,注入续写提示(continuation prompt)
关键组件:
loop-state-controller.ts:管理循环状态的 CRUDcompletion-promise-detector.ts:双通道检测完成continuation-prompt-builder.ts:构建带上下文的续写提示ralph-loop-event-handler.ts:事件驱动的循环控制器loop-session-recovery.ts:处理循环中的错误恢复
6.3 6.2 completion_promise 双通道检测
用户指定完成承诺(如 --completion-promise="all tests pass"),Ralph Loop 在 agent 输出中搜索该字符串。检测采用双通道策略:
- Transcript 文件扫描(快速、无网络开销):直接读 session 的 transcript 文件,搜索
completion_promise关键词 - Session Messages API(准确但慢):通过 API 查询最近的消息内容
先尝试 transcript 文件,失败再回退到 API。这比简单的"agent 说 done 就停"要可靠得多——agent 可能说"I’m done"但实际上测试还没跑。<promise>DONE</promise> 标签机制让 agent 能够明确表达"任务已完成",避免无限循环。
6.4 6.3 Ultrawork 变体与续写 prompt
ulw-loop 是 Ralph Loop 的增强版,在续写提示前触发 ultrawork 模型覆盖。
Ultrawork 模型覆盖的实现(src/plugin/chat-message.ts):
applyUltraworkModelOverrideOnMessage()检测消息中是否包含 “ultrawork”/“ulw” 关键词- 如果检测到,通过
scheduleDeferredModelOverride()在 microtask 中修改 SQLite,切换到更强大的模型 - 巧妙之处:TUI 底栏仍显示原始模型,但 API 调用使用覆盖后的模型——这是一个非常 hack 但有效的方案,利用了 OpenCode 读取模型配置和实际发送 API 请求之间的时间差
续写 prompt 由 continuation-prompt-builder.ts 构建,包含:
- 当前迭代进度(如 “Iteration 3/10”)
- 原始用户任务描述
- 完成承诺格式提醒
- 上下文信息(之前的工作进展)
这确保了 agent 在每次续写时都能回忆起完整的任务上下文,不会因为上下文压缩而丢失关键信息。
7 七、Hook 系统与消息拦截
OMO 通过 OpenCode 的插件 hook 机制,在 AI 交互的各个阶段注入自定义逻辑。
7.1 Hook 触发点图
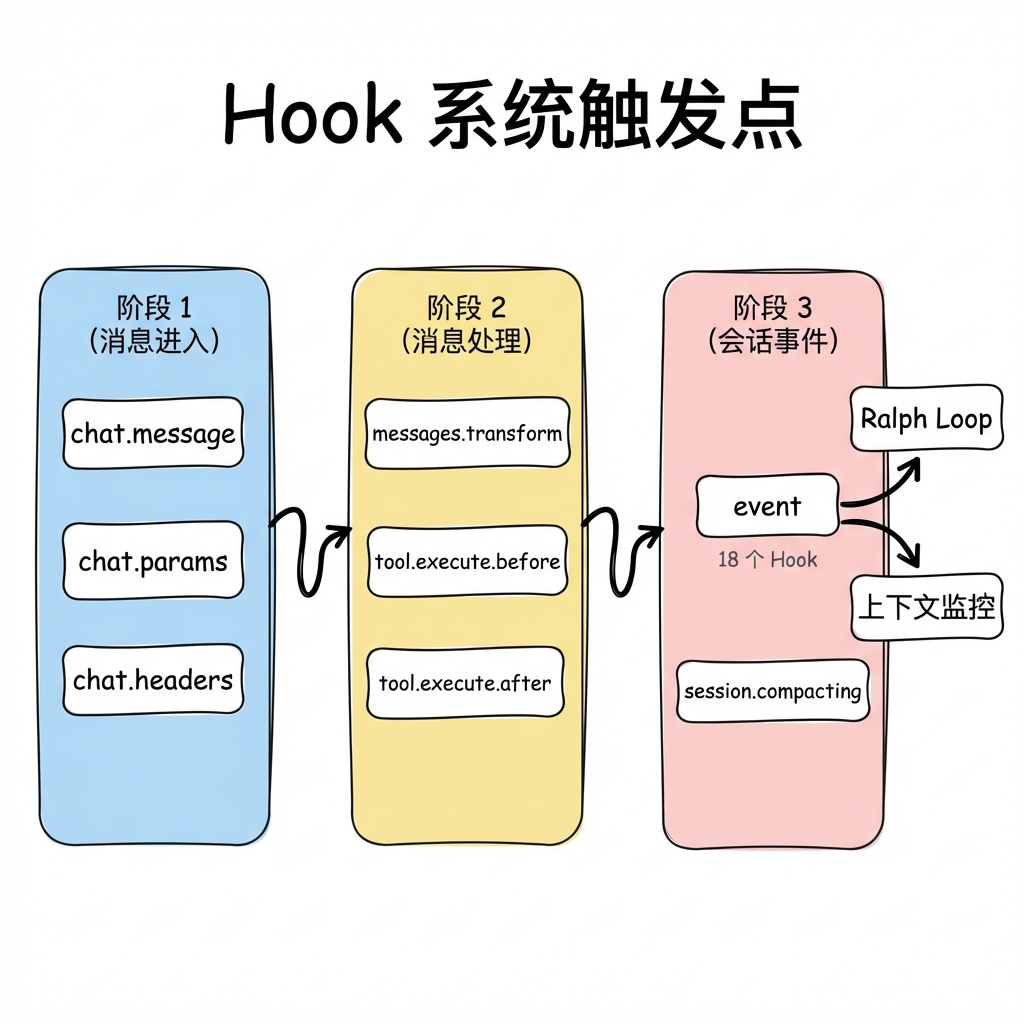
7.2 7.1 Hook 创建与分发
Hook 创建由 src/create-hooks.ts 统一编排,分为三大类:
|
|
安全机制:safeCreateHook() 包装器确保单个 hook 的创建失败不会影响整个插件启动。每个 hook 都可以通过 isHookEnabled() 独立启用/禁用。
createEventHandler()(src/plugin/event.ts)分发事件到 18 个 hook,按固定顺序执行:
|
|
这个顺序是有意义的:监控类 hook 先执行,然后是内容注入类,最后是控制流类。某些 hook 之间存在隐式依赖(如 stopContinuationGuard 必须在 ralphLoop 之后,确保用户主动停止时不自动恢复)。
7.3 7.2 Synthetic Idle 去重与事件处理
event.ts 实现了一个精巧的去重机制:
|
|
问题背景:OpenCode 的 session.status 事件中 status.type === "idle" 和 session.idle 事件可能在短时间内重复触发。normalizeSessionStatusToIdle() 将 session.status(idle) 转换为合成的 session.idle 事件,但这可能与真实的 session.idle 重复。解决方案:在 500ms 窗口内,如果已经处理了真实的 idle,就跳过合成的 idle,反之亦然。
关键 hook 简析:
- context-window-monitor:跟踪 token 使用量,区分 Anthropic 的"显示限制"(1M)和"实际限制"(200K 或 1M),避免 agent 被虚假的 token 计数误导
- preemptive-compaction:在上下文快满之前主动触发压缩,保留更多有用的上下文信息
- tool-output-truncator:根据模型上下文窗口大小动态决定截断阈值
- session-recovery:检测可恢复错误(如 API 超时),自动发送 “continue” 恢复会话
- anthropic-context-window-limit-recovery:专门处理 Anthropic API 上下文超限,实现 aggressive-truncation、deduplication-recovery、empty-content-recovery 多种恢复策略
- session-notification:跨平台通知(macOS AppleScript、Windows PowerShell toast、Linux),智能冲突检测避免与外部通知插件重复
特定事件处理:
- session.created:设置主会话、标记首消息变体门控、通知 tmux 会话管理器
- session.deleted:清理会话状态(agent 映射、消息游标、skill MCP 连接、tmux 面板)
- message.updated:跟踪每个会话当前使用的 agent
- session.error:检测可恢复错误,自动发送 “continue” 恢复会话
7.4 7.3 消息拦截链
createChatMessageHandler()(src/plugin/chat-message.ts)是最复杂的消息拦截器。一条消息进来后,依次经过:
|
|
Agent Variant 解析:
- 首消息使用
firstMessageVariantGate控制是否覆盖 variant - 后续消息根据 model 和 agent 解析 variant
- 支持 per-model variant 配置(
resolveVariantForModel)
每个 hook 都可以修改消息内容或触发副作用。这种混合模式灵活但也增加了调试难度——有些 hook 只读(keywordDetector),有些会修改输出(autoSlashCommand),有些会触发异步副作用(ralphLoop)。Ultrawork 延迟 DB 覆盖(六章已述)在此链末端执行。
7.5 7.4 Context Injector 与 Claude Code Hooks
Context Injector(src/features/context-injector/)实现优先级上下文注入系统。
ContextCollector(collector.ts)按 session 维护待注入条目,支持 4 级优先级:
|
|
每个条目有 source、id、content、priority、metadata。consume() 方法按优先级排序后合并所有条目,然后清空队列。
注入通过两种 hook 实现(injector.ts):
chat.messagehook:在输出的 text part 前插入上下文experimental.chat.messages.transformhook:在最后一条 user message 中插入 synthetic part(synthetic: true标记使其在 UI 中隐藏)
这是一个跨 hook 的数据共享机制——keyword-detector 和 claude-code-hooks 在处理消息时收集上下文,然后在 messages.transform 阶段统一注入。synthetic: true 标记既保证了 agent 能看到必要信息,又不污染用户的对话界面。
Claude Code Hooks 兼容层(src/hooks/claude-code-hooks/)是一个完整的子系统,提供与 Claude Code 原生 hooks 的兼容:
claude-code-hooks-hook.ts:总入口,创建 5 个处理器experimental.session.compacting— 压缩前处理chat.message— 消息拦截tool.execute.before— 工具执行前tool.execute.after— 工具执行后event— 事件处理
config-loader.ts/config.ts:加载 Claude Code 的 hooks 配置transcript.ts:管理对话 transcript 文件user-prompt-submit.ts:处理用户提交的 promptsession-hook-state.ts:维护 hook 的会话状态
设计意图:让用户在 Claude Code 中配置的 hooks(如 pre-tool-use、post-tool-use)能够在 OMO 的插件架构中正常工作,实现零成本迁移。
8 八、配置系统与 Model Fallback
8.1 8.1 多层配置合并与容错
配置来源(优先级从高到低):
- 项目级:
.opencode/oh-my-opencode.json[c] - 用户级:
~/.config/opencode/oh-my-opencode.json[c] - 内置默认值
支持 JSONC(带注释的 JSON,基于 jsonc-parser 库),用 Zod 做 schema 验证。detectConfigFile() 自动检测 .jsonc 和 .json 后缀,优先使用 .jsonc。
loadConfigFromPath()(src/plugin-config.ts)实现两级容错:
- 完整验证:
OhMyOpenCodeConfigSchema.safeParse()尝试完整解析 - 部分加载:验证失败时
parseConfigPartially()逐字段尝试——对每个顶层 key 单独做safeParse({ [key]: rawConfig[key] }),有效的保留、无效的跳过并记录错误
这确保了一个配置项的错误不会导致整个配置失效。
配置合并规则(mergeConfigs()):
agents/categories/claude_code:使用deepMerge()递归合并(带原型链污染防护,过滤__proto__/constructor/prototype,最大递归 50 层)disabled_*数组:使用 Set 去重后并集合并- 其他字段:简单覆盖(
...base, ...override)
Schema 设计特点(src/config/schema/oh-my-opencode-config.ts):全字段 optional(支持最小化配置)、模块化子 schema、统一的 disabled_* 模式覆盖 agents/mcps/hooks/commands/skills/tools 六个维度、_migrations 字段记录已应用的迁移。
8.2 8.2 双层 Model Fallback
安装时和运行时存在两套独立的 fallback 机制,这不是冗余而是有意为之——安装时基于用户声明的订阅状态做静态配置,运行时基于实际可用模型做动态降级。两层机制覆盖了"用户知道自己有什么"和"系统发现实际有什么"两种场景。
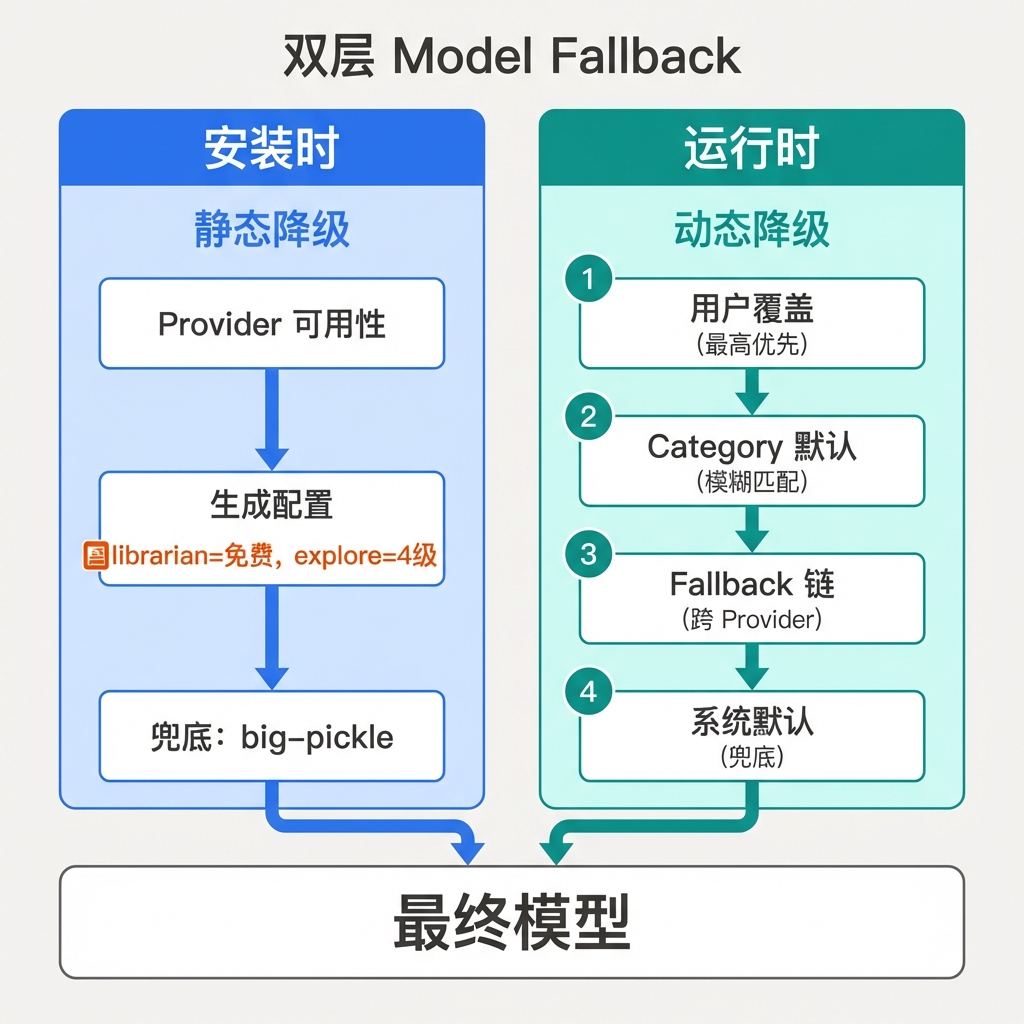
安装时静态降级(src/cli/model-fallback.ts):
基于 ProviderAvailability 布尔结构体(用户声明的订阅状态),通过 generateModelConfig() 生成静态配置文件。简单、确定性强。
特殊处理:
- librarian 固定使用
opencode/minimax-m2.5-free(免费模型) - explore 有独立的 4 级降级逻辑
- sisyphus 使用
requiresAnyModel约束 - 无任何 provider 时全部使用
ULTIMATE_FALLBACK(opencode/big-pickle)
运行时动态降级(src/shared/model-resolution-pipeline.ts):
基于实际可用的模型列表(从 OpenCode API 或缓存获取),实现四级优先级管道:
|
|
解析流程:
- UI 选择 / 用户覆盖:直接返回,不做可用性检查(信任用户意图)
- Category 默认:先尝试 fuzzy match 可用模型集;若模型集为空,回退到 connected-providers-cache 检查 provider 是否连接
- Fallback Chain:遍历链中每个 entry,对每个 provider 做 fuzzy match;还支持跨 provider 模糊匹配作为最后手段
- 系统默认:兜底模型
解析结果携带 provenance 字段标记模型来源(override / category-default / provider-fallback / system-default),便于调试和日志追踪。
Agent 模型需求矩阵(src/shared/model-requirements.ts)定义每个 agent 的降级链:
| Agent | 首选模型 | 降级路径 | 特殊约束 |
|---|---|---|---|
| sisyphus | claude-opus-4-6 (max) | → kimi-k2p5 → glm-5 → big-pickle | requiresAnyModel |
| hephaestus | gpt-5.3-codex (medium) | 无降级 | requiresProvider: openai/copilot/opencode |
| oracle | gpt-5.2 (high) | → gemini-3-pro → claude-opus-4-6 | — |
| prometheus | claude-opus-4-6 (max) | → gpt-5.2 → kimi → gemini-3-pro | — |
| librarian | gemini-3-flash | → minimax-m2.5-free → big-pickle | — |
| explore | grok-code-fast-1 | → minimax-m2.5-free → claude-haiku → gpt-5-nano | — |
每个 provider 列表中通常包含 github-copilot 和 opencode 作为备选通道,同一个模型可以通过不同的 API 网关访问。
CATEGORY_MODEL_REQUIREMENTS 定义了 8 个语义化 category 的模型偏好:
| Category | 首选模型 | 选择理由 |
|---|---|---|
| visual-engineering | gemini-3-pro | 视觉能力 |
| ultrabrain | gpt-5.3-codex xhigh | 最强推理 |
| deep | gpt-5.3-codex medium | 深度执行 |
| artistry | gemini-3-pro | 创意生成 |
| quick | claude-haiku-4-5 | 速度优先 |
| unspecified-low | claude-sonnet-4-6 | 通用低成本 |
| unspecified-high | claude-opus-4-6 max | 通用高质量 |
| writing | kimi-k2p5 | 长文写作 |
8.3 8.3 fuzzy match 与配置迁移
fuzzyMatchModel()(src/shared/model-name-matcher.ts / model-availability.ts)的匹配策略:
- 大小写不敏感
- 版本号标准化(
claude-opus-4-6↔claude-opus-4.6) - 子串匹配
- 优先级排序:精确匹配 > 精确 model ID 匹配 > 最短匹配
connected-providers-cache.ts 实现两级缓存:connected-providers.json(已连接 provider ID 列表)和 provider-models.json(每个 provider 的可用模型列表),通过 updateConnectedProvidersCache() 从 OpenCode SDK 刷新。
配置迁移系统(src/shared/migration/config-migration.ts)编排四种迁移:
- Agent 名称:
omo/OmO→sisyphus,OmO-Plan→prometheus,orchestrator-sisyphus→atlas,plan-consultant→metis - Hook 名称:
anthropic-auto-compact→anthropic-context-window-limit-recovery,sisyphus-orchestrator→atlas - 模型版本:
openai/gpt-5.2-codex→openai/gpt-5.3-codex,anthropic/claude-opus-4-5→anthropic/claude-opus-4-6 - 字段迁移:
omo_agent→sisyphus_agent,experimental.hashline_edit→ 顶层hashline_edit
安全机制:
_migrations记录防止重复迁移(用户手动回退模型版本后不会被再次自动升级)- 迁移前创建带时间戳的
.bak备份 - 内存回写确保即使文件写入失败也能生效
disabled_agents/disabled_hooks同步迁移名称
8.4 8.4 Skill 系统六源发现
src/features/opencode-skill-loader/loader.ts 实现六源 Skill 发现,按优先级去重:
|
|
Skill 加载管线:skill-directory-loader.ts(目录扫描)→ skill-content.ts(解析内容和 frontmatter)→ skill-deduplication.ts(按名称去重,先出现的优先)→ merger/(合并来自不同源的定义)。
内置 5 个技能(src/features/builtin-skills/skills.ts):playwright / playwright-cli / agent-browser(三选一,由 browserProvider 配置决定)、frontend-ui-ux、git-master、dev-browser。
SkillMcpManager(src/features/skill-mcp-manager/manager.ts)管理 Skill 关联的 MCP 连接:以 sessionID:skillName:serverName 为 key 复用连接,withOperationRetry() 最多重试 3 次,支持 OAuth step-up 认证升级,双传输支持(stdio + HTTP/SSE)。
9 九、Claude Code 兼容层
OMO 能加载 Claude Code 生态的资源(commands、agents、MCP servers、plugins、skills、hooks),让用户从 Claude Code 迁移到 OpenCode + OMO 时零成本复用已有配置。这是一个很有商业头脑的设计——OMO 不只是 OpenCode 的插件,它还能加载 Claude Code 生态的资源。
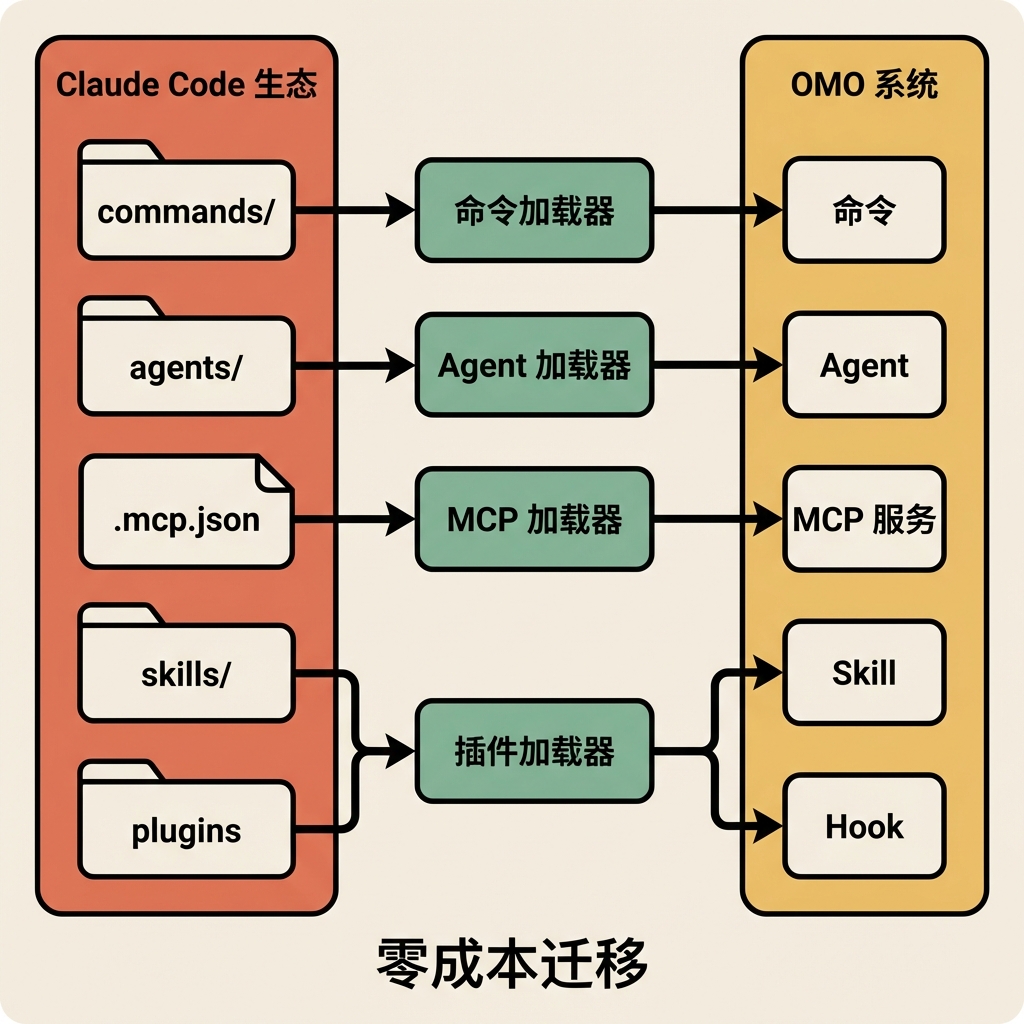
四个 Loader 各司其职:
claude-code-plugin-loader(src/features/claude-code-plugin-loader/loader.ts)是兼容层的顶层入口,discovery.ts 在 node_modules 中扫描符合 Claude Code 插件规范的包,并行加载 commands、skills、agents、mcpServers、hooksConfigs,带 10 秒超时保护防止插件加载阻塞启动。
claude-code-command-loader(src/features/claude-code-command-loader/loader.ts)从四个位置加载 Markdown 命令文件:
| 优先级 | 路径 | 作用域 |
|---|---|---|
| 1 | {cwd}/.opencode/command/ |
opencode 项目级 |
| 2 | ~/.config/opencode/command/ |
opencode 全局 |
| 3 | {cwd}/.claude/commands/ |
Claude Code 项目级 |
| 4 | ~/.claude/commands/ |
Claude Code 用户级 |
命令文件使用 frontmatter 格式,支持 description、agent、model、subtask、handoffs 等元数据。模板中 $ARGUMENTS 占位符在执行时替换为用户输入。
claude-code-agent-loader(src/features/claude-code-agent-loader/loader.ts)从 ~/.claude/agents/ 和 {cwd}/.claude/agents/ 加载 Markdown 格式的 agent 定义,Markdown body 作为 agent prompt,frontmatter 中的 tools 字段转换为工具权限配置。
claude-code-mcp-loader(src/features/claude-code-mcp-loader/loader.ts)从四个位置加载 .mcp.json 配置(~/.claude.json、~/.claude/.mcp.json、{cwd}/.mcp.json、{cwd}/.claude/.mcp.json),transformer.ts 将 Claude Code 格式转换为 OpenCode 兼容格式,env-expander.ts 处理环境变量展开。
| 资源类型 | Claude Code 路径 | OpenCode 路径 | 优先级 |
|---|---|---|---|
| 命令 | ~/.claude/commands/ |
~/.config/opencode/command/ |
OpenCode > Claude Code |
| 命令(项目) | {cwd}/.claude/commands/ |
{cwd}/.opencode/command/ |
OpenCode > Claude Code |
| Agent | ~/.claude/agents/ / {cwd}/.claude/agents/ |
— | 直接加载 |
| MCP | ~/.claude.json / ~/.claude/.mcp.json / {cwd}/.mcp.json |
— | 直接加载 |
| Skill | ~/.claude/skills/ / {cwd}/.claude/skills/ |
~/.config/opencode/skills/ / {cwd}/.opencode/skills/ |
OpenCode > Claude Code |
10 十、创新亮点深度解析

-
AgentPromptMetadata 自描述系统:多 agent 系统中主编排 agent 需要知道所有可用 agent 的能力,传统做法是在主 agent 的 prompt 中硬编码。OMO 让每个 agent 通过
AgentPromptMetadata声明式描述自己,dynamic-agent-prompt-builder.ts自动聚合生成 Delegation Table 等段落。添加新 agent 不需要修改 Sisyphus 的代码,第三方插件注册的 agent 也能通过buildCustomAgentMetadata()自动融入,实现了真正的开放-封闭原则。 -
Hashline Edit 防幻觉编辑:AI 基于过时文件内容生成编辑指令时,传统精确文本匹配会静默失败。Hashline Edit 用 2 字符 CID 哈希(16^2 = 256 种组合)标记每行,哈希不匹配则拒绝编辑并提示重新读取,将"文件是否过时"的检测前置到工具层。2 字符哈希在 token 开销和碰撞率之间取得了平衡——对于单个文件的行数来说碰撞概率极低。
-
Ralph Loop completion_promise:AI agent 单次对话可能无法完成复杂任务(上下文窗口限制、任务复杂度),且"agent 说 done 就停"不可靠——agent 可能说"I’m done"但实际上测试还没跑。用户指定 completion_promise 将"完成"的定义权交给用户,双通道检测(transcript 文件扫描 + Session Messages API 回退)在速度和准确性之间取得平衡。
-
双轨主 Agent(Sisyphus vs Hephaestus):不同任务需要不同行为模式——有些适合快速委派(“帮我查一下这个 API”),有些适合深度自主执行(“重构整个认证模块”)。Sisyphus 委派优先适合协调型任务,Hephaestus 自主优先适合深度执行。Prompt 工程实践表明,行为模式切换比参数微调更可靠——LLM 对"你是管理者"和"你是执行者"的响应差异远大于"autonomy=0.7 vs 0.3"。
-
三级并发控制 + settled-flag:不同模型 rate limit 不同,简单全局限制要么浪费 Haiku 高并发能力,要么触发 Opus rate limit。三级粒度(模型 > Provider > 全局)允许精细控制(如 Opus 并发 1,Haiku 并发 10),同时提供合理的默认值。settled-flag 是对 Promise 语义的防御性编程——虽然 JS 单线程模型在大多数情况下保护了这一点,但显式标志消除了所有边界情况。
-
TmuxSessionManager QDEU 架构:tmux 状态管理容易出现内部缓存与实际 pane 不一致,尤其在并发操作和异常恢复场景下。Query-Decide-Execute-Update 四步架构将 tmux 实际状态作为唯一真实来源,内部 Map 仅作缓存,纯函数
decideSpawnActions()使决策逻辑可测试。 -
Prometheus 三段式质量链:AI 生成的计划可能遗漏关键步骤、引用不存在的文件、或包含不可执行指令。Metis(前置 gap 分析)→ Prometheus(计划生成)→ Momus(后置审查)使用不同 agent 和视角,避免"自己审查自己"的盲点。Momus 的 APPROVAL BIAS 是务实的——过度严格的审查会导致无限修改循环,浪费 token。
-
Context Injector Synthetic Part:hook 系统需要向 agent 注入上下文(如 keyword 检测结果、Claude Code hooks 输出)但不应出现在用户界面。通过
synthetic: true标记的 part 利用 OpenCode 的 UI 渲染机制实现"agent 可见、用户不可见"的信息注入,不污染对话历史,也不占用 system prompt 空间。
11 十一、问题与改进建议
11.1 11.1 复杂度热点
| 模块 | 问题 | 建议 |
|---|---|---|
delegate-task/tools.ts |
220+ 行,承担参数验证/Skill 解析/模型选择/category 路由等多重职责 | 进一步拆分为独立函数 |
agent-config-handler.ts |
226 行处理迁移/发现/创建/合并/排序 | 拆分为 agent-migrator、agent-discoverer、agent-merger |
tool-execute-before |
承担 hook 分发/task 路由/ralph-loop 解析/stop-continuation | 按职责拆分 |
| Sisyphus prompt | 约 500 行,随 agent/category/skill 增加持续膨胀 | 引入 prompt 分层加载或压缩 |
chat-message.ts |
Ralph Loop 检测重复存在于此和 tool-execute-before.ts |
统一入口,避免状态不一致 |
11.2 11.2 硬编码与魔数
| 位置 | 魔数 | 风险 |
|---|---|---|
lsp-client.ts:37 |
setTimeout(r, 1000) openFile 后等待 |
不同 LSP 服务器可能不够或过长 |
lsp-client.ts:97 |
setTimeout(r, 500) diagnostics 前等待 |
同上 |
manager.ts:295 |
setTimeout(r, 200) tmux callback 后等待 |
高负载下可能不足 |
event.ts |
DEDUP_WINDOW_MS = 500 synthetic idle 去重 |
缺乏自适应能力 |
更好的方案是等待特定的 LSP 通知(如 textDocument/publishDiagnostics)或 tmux pane 就绪信号,而非硬编码等待时间。
11.3 11.3 代码重复与一致性
| 问题 | 位置 | 建议 |
|---|---|---|
fuzzyMatchModel() 重复实现 |
model-name-matcher.ts + model-availability.ts |
合并为单一实现 |
| Ralph Loop 启动逻辑重复 | chat-message.ts + tool-execute-before.ts |
统一入口 |
安装时 librarian 硬编码 minimax-m2.5-free,运行时首选 gemini-3-flash |
CLI vs shared | 统一模型选择逻辑 |
disabled_* 并集合并 |
项目级无法"取消"用户级禁用项 | 支持显式启用覆盖 |
配置迁移 JSON.stringify 写回 |
丢失 JSONC 注释 | 使用保留注释的序列化 |
| 自定义 Agent 元数据过于简化 | 统一 category: "specialist", cost: "CHEAP" |
允许外部 agent 声明真实成本 |
11.4 11.4 可靠性风险
- BackgroundManager 的
tasksMap 在高并发场景下有内存泄漏风险(依赖定时器清理,notifyParentSession()持续失败时任务可能在completionTimers中积累) - MCP 全部依赖远程服务,网络不可用时完全不可用,缺乏本地 fallback
- 全局状态(
getMainSessionID()、subagentSessions等)在多模块间共享,增加测试难度和并发风险 - 18 个 hook 的调用顺序硬编码且存在隐式依赖,顺序被意外修改可能导致难以调试的问题
- Plugin Components 加载的 10 秒超时对网络环境差的情况可能不够,但对快速启动又太长,缺乏重试机制
- 多处使用
.catch(() => {})静默吞掉错误(如 toast 通知、session prompt),虽然防止了崩溃,但可能掩盖真实问题
12 十二、总体评价
12.1 亮点
-
Agent 编排设计成熟:不是简单的"多个 agent 轮流说话",而是有明确的职责分工、成本意识、工具权限隔离和动态 prompt 构建。AgentPromptMetadata 自描述系统实现了真正的开放-封闭原则。这是我见过的开源项目中最完善的 multi-agent 编排方案之一。
-
工程质量高:测试覆盖充分(256 个测试文件,67k 行测试代码——几乎等于实现代码量),类型安全(Zod schema + TypeScript),错误处理完善(settled-flag 防 double-resolution、session recovery、error classifier、渐进式容错配置加载),日志系统完整。
-
用户体验考虑周到:tmux 可视化让后台 agent 不再是黑盒,Toast 通知让用户知道发生了什么,Ralph Loop 的 completion_promise 让自动化可控,Hashline Edit 防止 AI 编辑过时内容。
-
生态兼容性强:Claude Code 兼容层覆盖了全部扩展点(commands、agents、MCP servers、plugins、skills、hooks),路径兼容让用户零成本迁移。
-
配置灵活但有默认值:开箱即用,但几乎所有行为都可以通过配置调整。双层 Model Fallback(安装时静态 + 运行时动态)确保总能找到可用模型。渐进式容错确保单个配置项错误不影响全局。
12.2 最终判断
Oh My OpenCode 是一个工程质量很高、设计理念先进的项目。它不是一个简单的配置文件集合,而是一个真正的 multi-agent 编排框架,恰好以 OpenCode 插件的形式存在。
作者(YeonGyu Kim)显然对 AI agent 的实际使用有深入理解——从 Sisyphus prompt 中"不要 shotgun debug"、“Oracle 的价值在你觉得不需要它的时候最高"这些细节就能看出来。这不是纸上谈兵,而是大量实际使用经验的结晶。
如果你在用 OpenCode,OMO 值得一试。如果你在研究 multi-agent 编排,OMO 的 agent 体系和 prompt 工程值得深入学习。
欢迎关注我的公众号~
