20块钱20分钟,Manus帮我"蒸馏"了腾讯智能渗透挑战赛的精华
最近腾讯办了一场智能渗透挑战赛,参赛选手需要编写以大语言模型(LLM)为核心驱动的智能体程序,完成靶机的自动化渗透并获取FLAG。比赛旨在推动AI大模型与网络安全技术的深度融合,探索智能体在自动化渗透测试领域的应用潜力。
比赛结束后,排名靠前的队伍进行了思路分享,部分队伍开放了PPT和源代码。作为一个对AI Agent架构很感兴趣的人,我一直想对这些获奖队伍做一个深度分析。但问题是队伍太多了,涉及到设计思路、代码、PPT、视频等各种形式的资料,人工整理工作量巨大。
最近Manus被收购的消息传得火热,上次体验已经是很久之前的事了,这次想借这个机会测试一下它的最新能力:能不能帮我快速完成这17支队伍的资料收集、代码分析、架构总结,并进行深度分析,最后提炼出一个"博取百家之长"的终极安全渗透智能体架构。
1 任务描述
任务链接:https://zc.tencent.com/competition/competitionHackathon?code=cha004
具体来说,我给Manus布置了以下任务:
|
|
2 Manus Lite初体验:有点失望
Manus提供了免费的Lite版本,发送prompt后开始执行任务。刚开始Manus的表现还算正常,它理解了我的任务意图,开始访问比赛页面收集信息,通过编写JavaScript代码来提取关键信息。
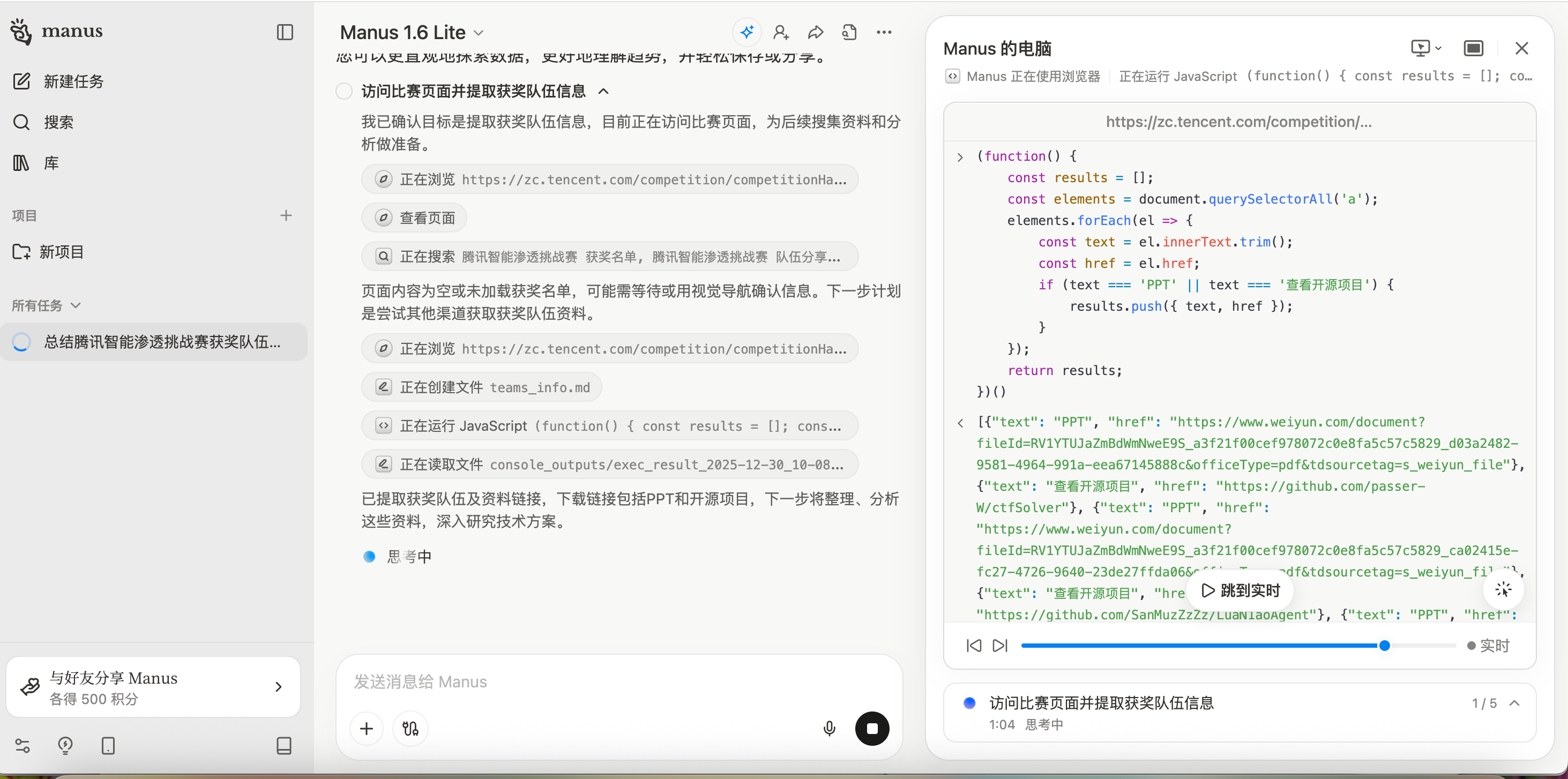
Manus展现出了一定的信息组织能力,它创建了summary.md来整理收集到的战队信息,包括队伍名称、核心策略、技术亮点等。
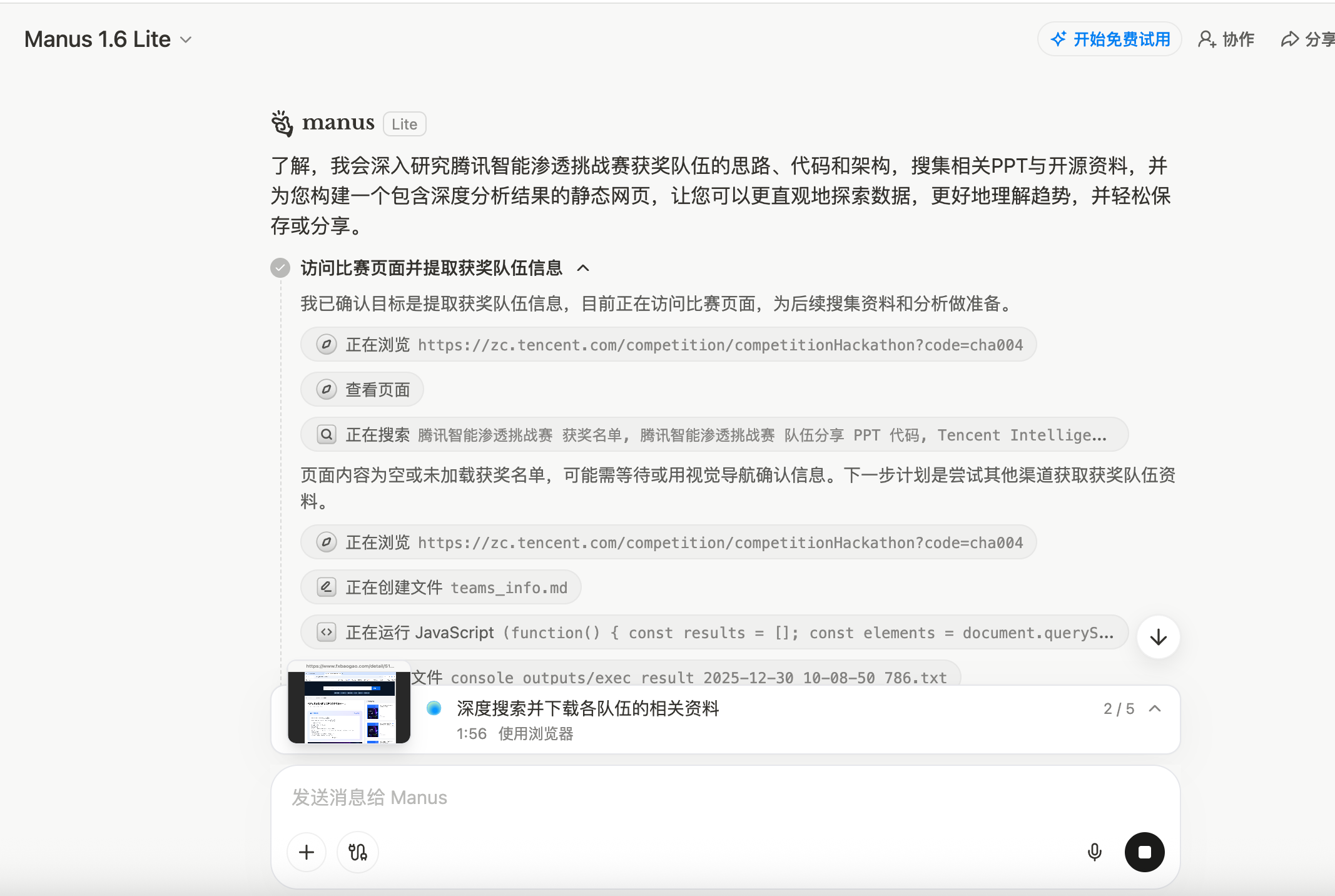
但Lite版本的问题很快暴露出来了。总共16支队伍,只分析了7个,最后生成的网站只剩4个。整体的分析深度不够,只是浮于表面地收集了一些基本信息,没有深入到代码层面。
生成的网页内容也非常简略,战队深度分析页面只有简单的核心方案描述,缺少真正的技术细节,达不到我想要的"深度分析"的要求。
看来是钱没到位。这种复杂的分析任务,可能需要更高级的版本才能处理好。
3 咸鱼购买Manus Pro:真正的体验开始
直接买会员太贵了,于是打开万能的咸鱼,购买了自带积分的Manus Pro 7天账号,直接开启MAX模式。
切换到Max版本后,Manus的行为明显不一样了。它开始系统性地规划整个任务,收集各队伍的信息并建立本地文件系统来记录进展,列出了明确的执行步骤:收集比赛信息和各队伍资料、深度分析每个战队的Agent架构设计、生成综合分析报告、设计最优安全渗透智能体架构、构建交互式静态网页展示研究结果。任务分解的逻辑相当清晰。
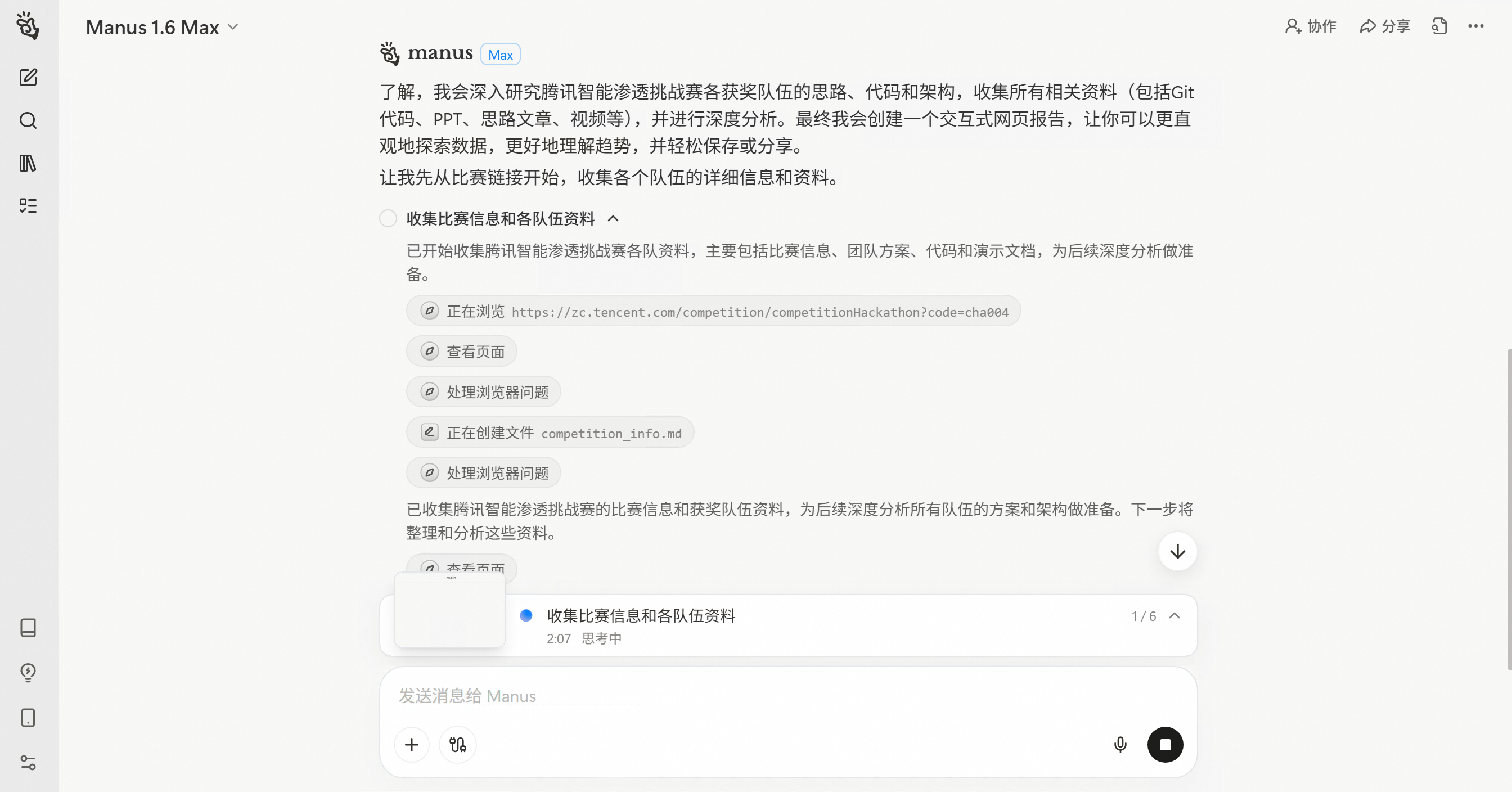
Manus开始执行任务后,展现出了强大的浏览器自动化能力。它访问比赛官网和各种技术文章,系统性地收集所有相关信息。从下图可以看到,Manus在分析量子位的一篇关于这次比赛的报道,同时还在浏览比赛官方页面。
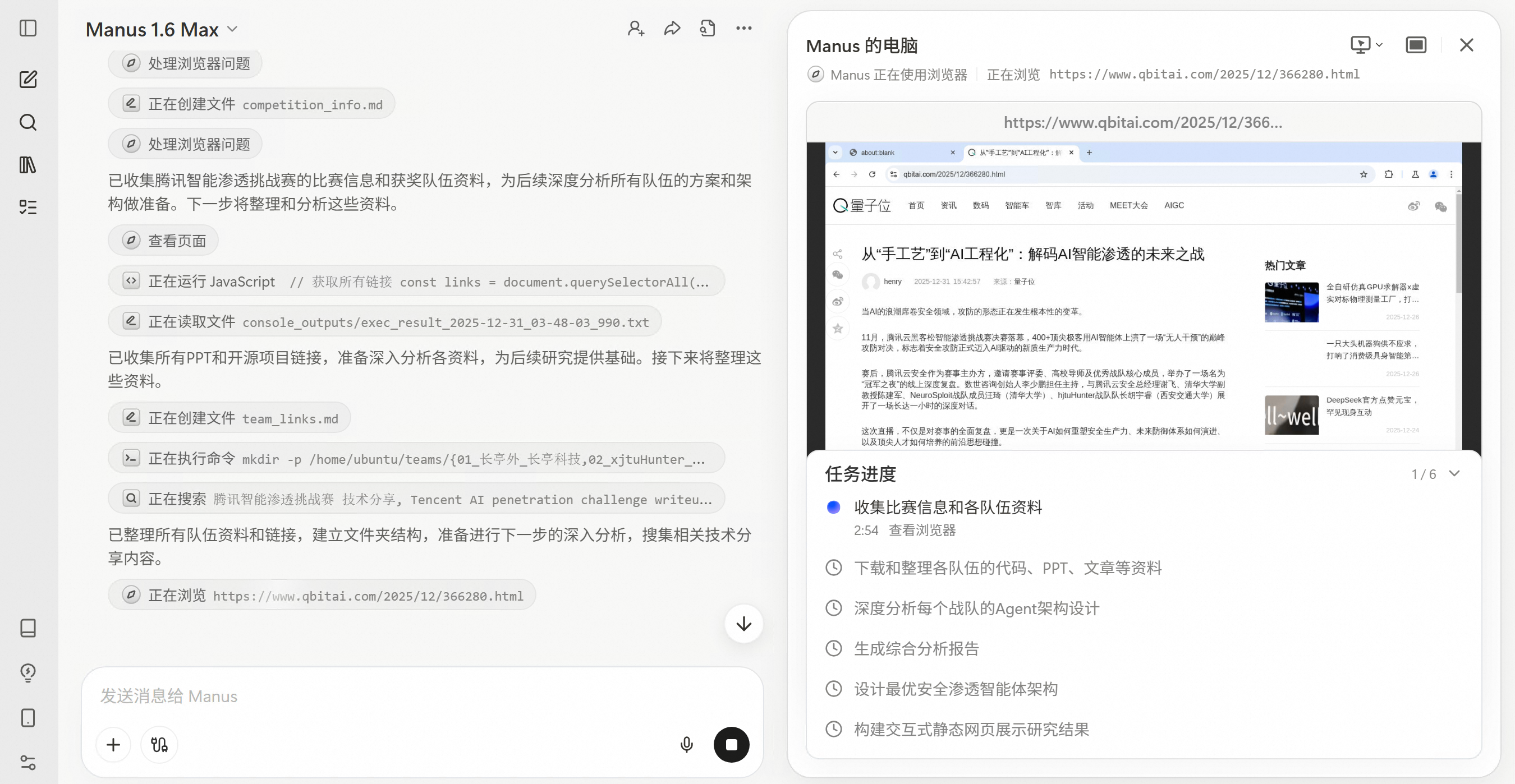
Manus的浏览器功能确实让人印象深刻。它能够灵活地操控浏览器,获取页面信息的速度很快,滑动、点击等操作都很流畅。它创建了teams_info.md文件来系统性地记录每个队伍的信息,包括队伍名称和排名、核心策略、GitHub代码链接、PPT资料链接和技术亮点等。
可以看到它收集了17支队伍的详细信息,包括长亭外、xjtuHunter、BinX、Antix、Pachinko、NeuroSploit等排名靠前的队伍。Manus甚至可以自己写JS代码来获取页面内容并整理成表格,相当于一个自动化爬虫。相比我自己用browser use之类的工具,成功率明显高很多。
当然也遇到了一些问题。在访问某些网站时,Manus触发了风控验证,目前的版本还无法自动绕过这类验证码,只能跳过这些资源继续执行其他任务。
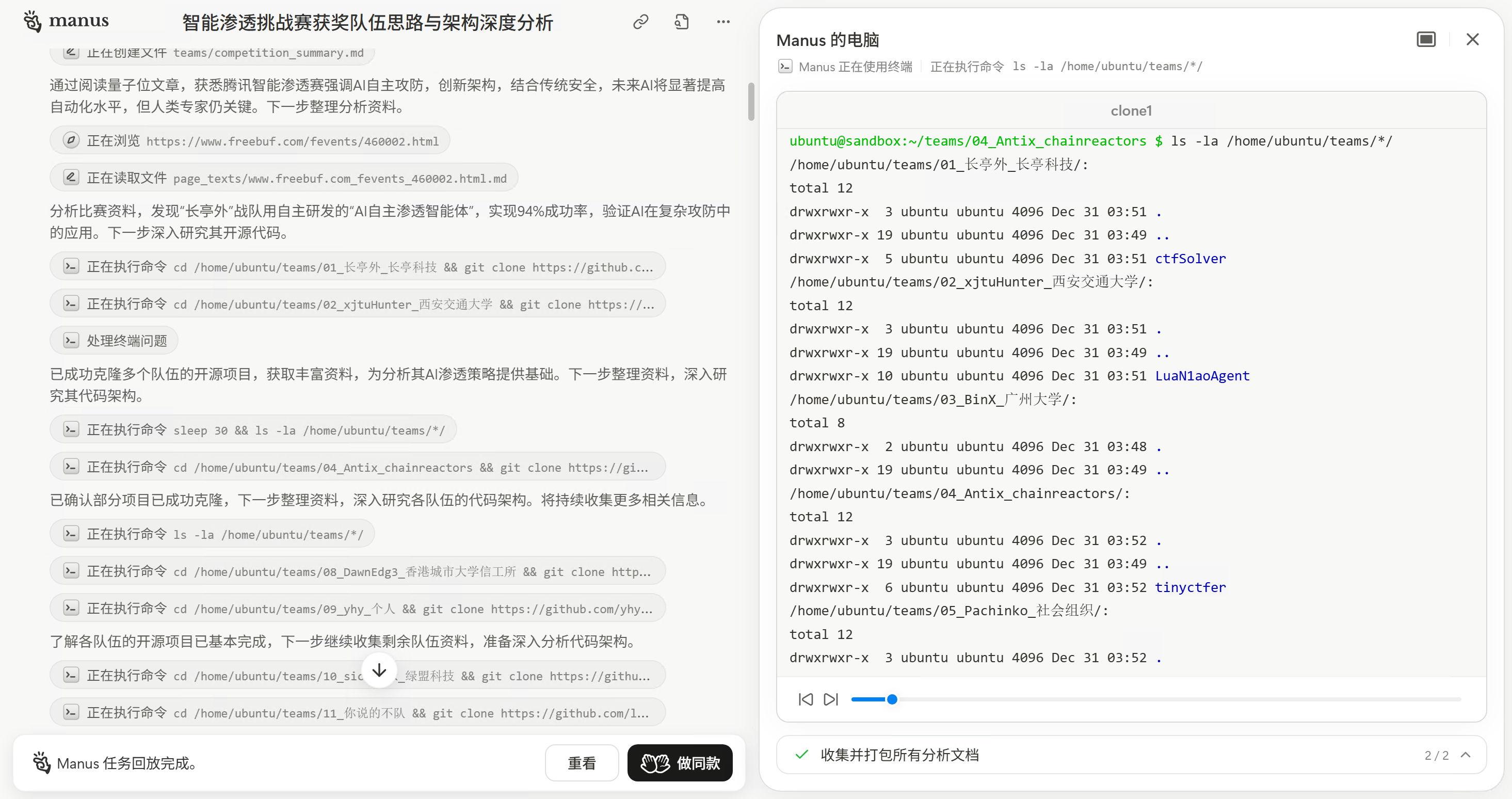
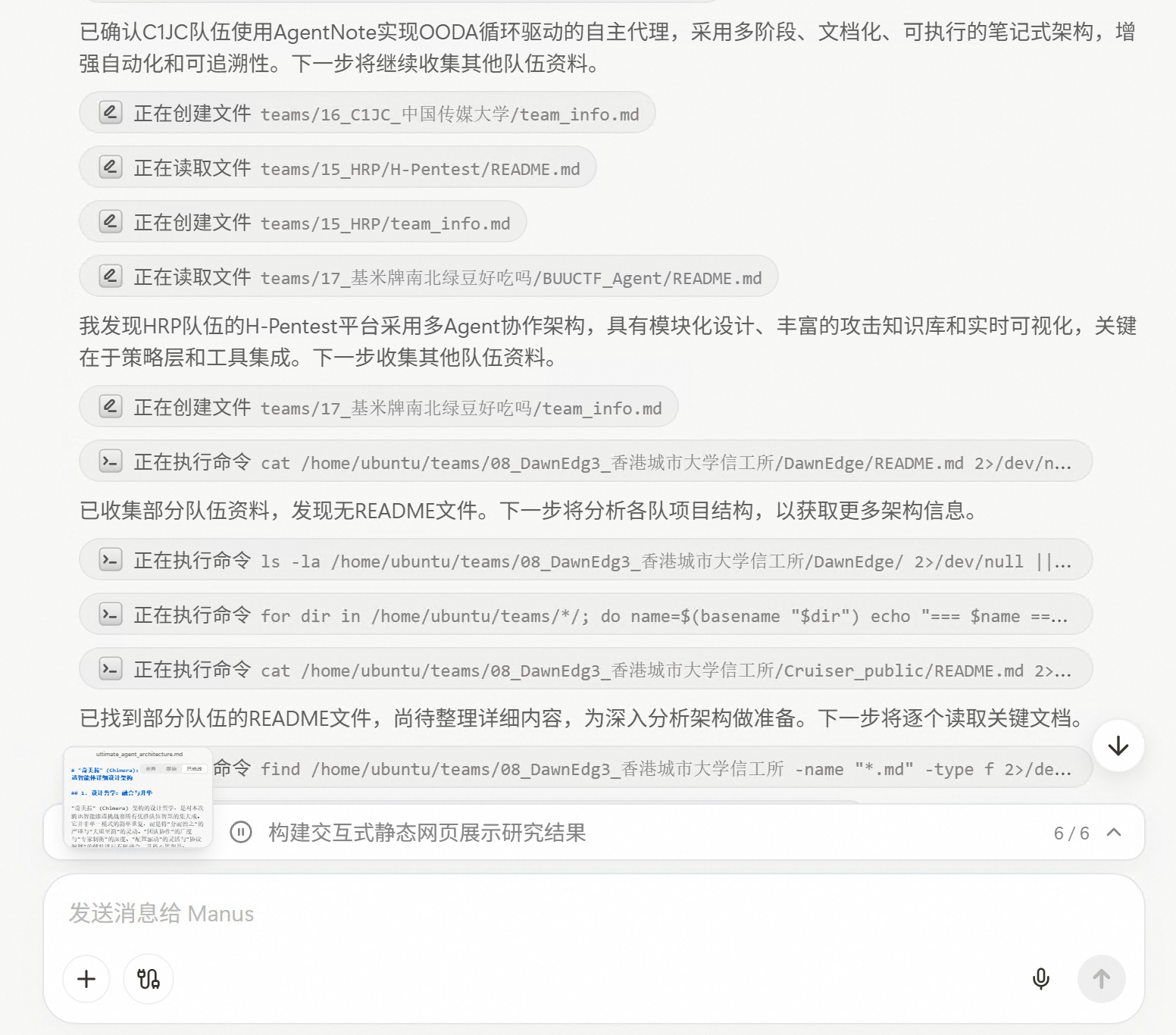
Manus对文件系统的灵活运用让人印象深刻。它会随时随地新建文件来记录进展,把收集到的信息、分析结果、中间思考都保存下来。这种做法既能防止长任务中信息丢失,也方便后续的整理和分析。
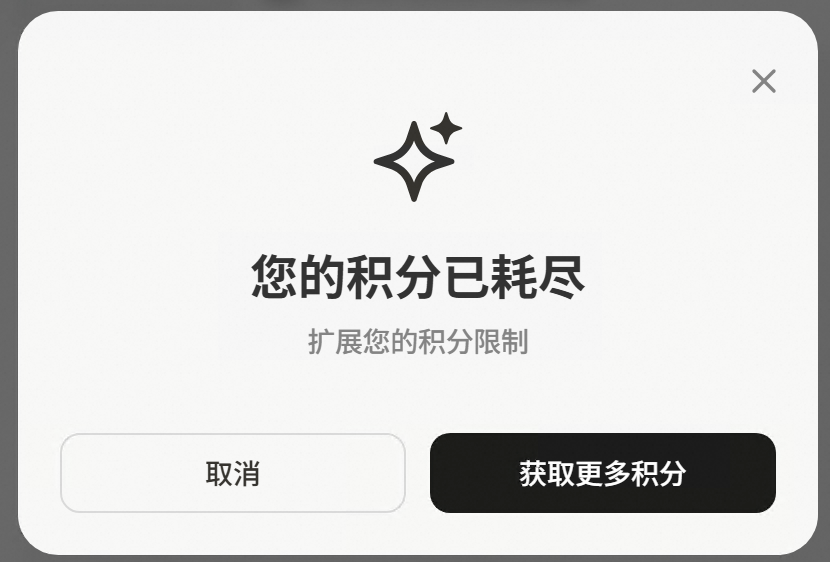
正当我沉浸在观察Manus工作的过程中,突然弹出了积分耗尽的提示。2000+积分一下子就没了,这个消耗速度确实超出预期。Max版本的能力是强,但成本也是真的高。赶紧又去咸鱼用2000积分续上。
4 引导优化:借助DeepWiki深入分析
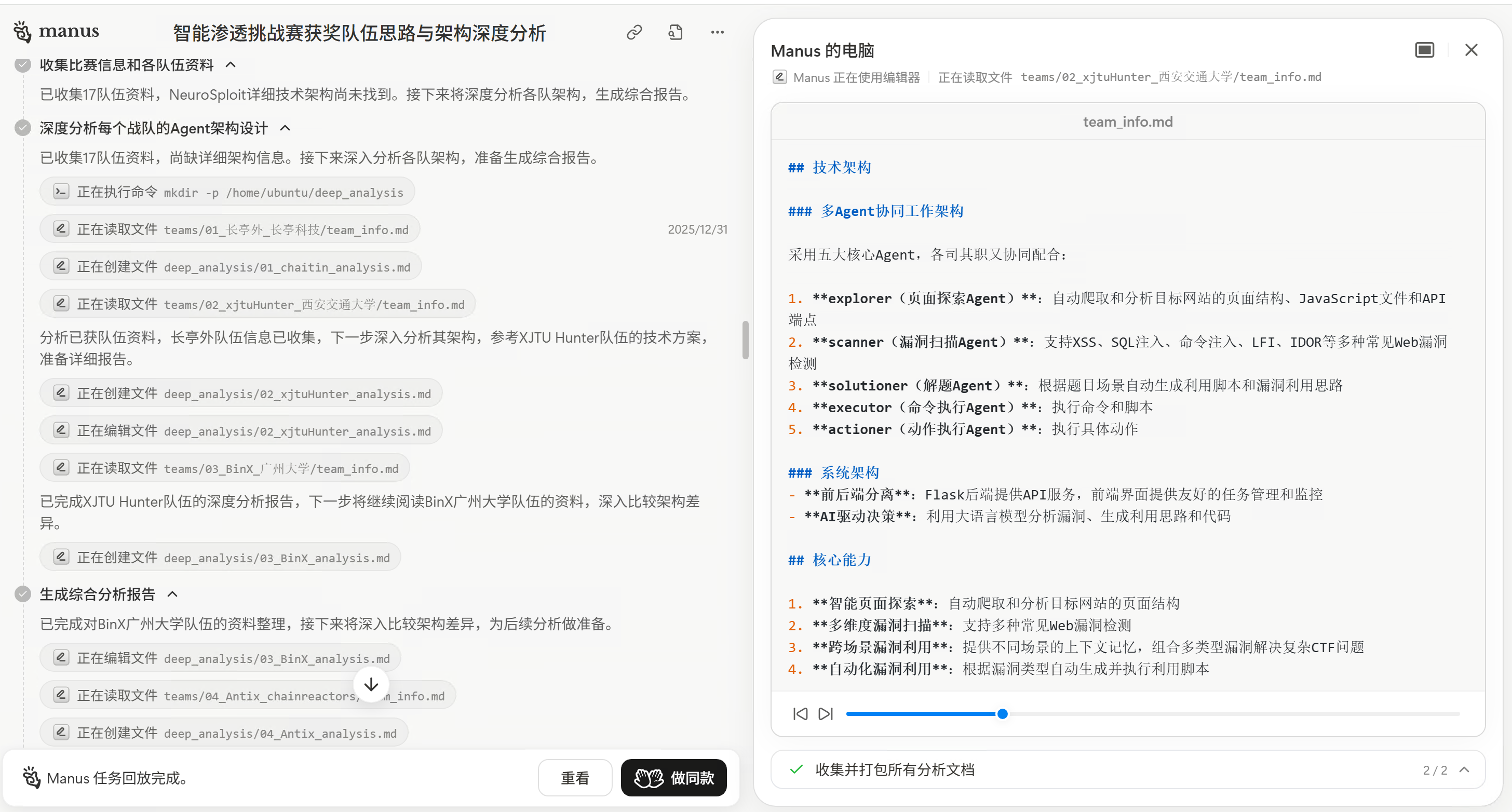
看到Manus Pro的分析结果后,我发现虽然它收集了大量资料,但对各个战队代码项目结构的分析还不够深入。于是我给它提供了一个优化提示:
|
|
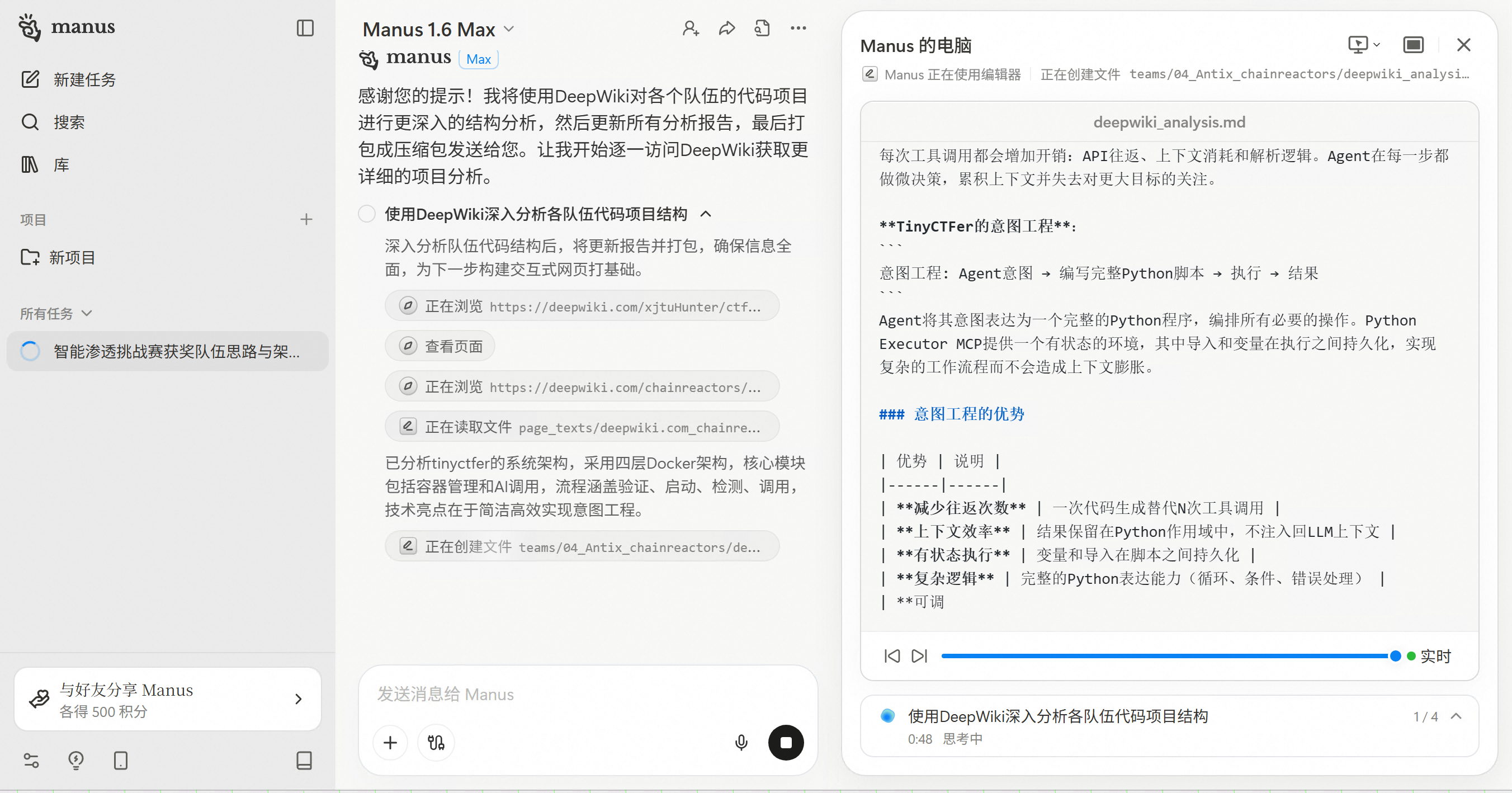
接收到这个提示后,Manus立刻调整了策略,开始更深入地分析各个队伍的代码架构,利用DeepWiki对各个GitHub仓库进行深度分析,生成了更详细的架构分析报告。
5 最终成果展示
经过多轮交互和积分充值,Manus最终完成了任务。
成果相当丰富:12+队伍的详细分析报告、综合分析报告(包含17支队伍的横向对比、两大主流设计思想、六大核心架构模式总结)、终极架构设计"奇美拉"(Chimera)、以及交互式静态网页。
生成的网页效果:https://aipentest-dbvbgpwp.manus.space/
最终生成的网页设计得相当精美,采用深色科技感主题,首页展示了深度分析17支优胜队伍的Agent架构设计、技术亮点与创新思路,提炼最佳实践并设计下一代安全渗透智能体架构。

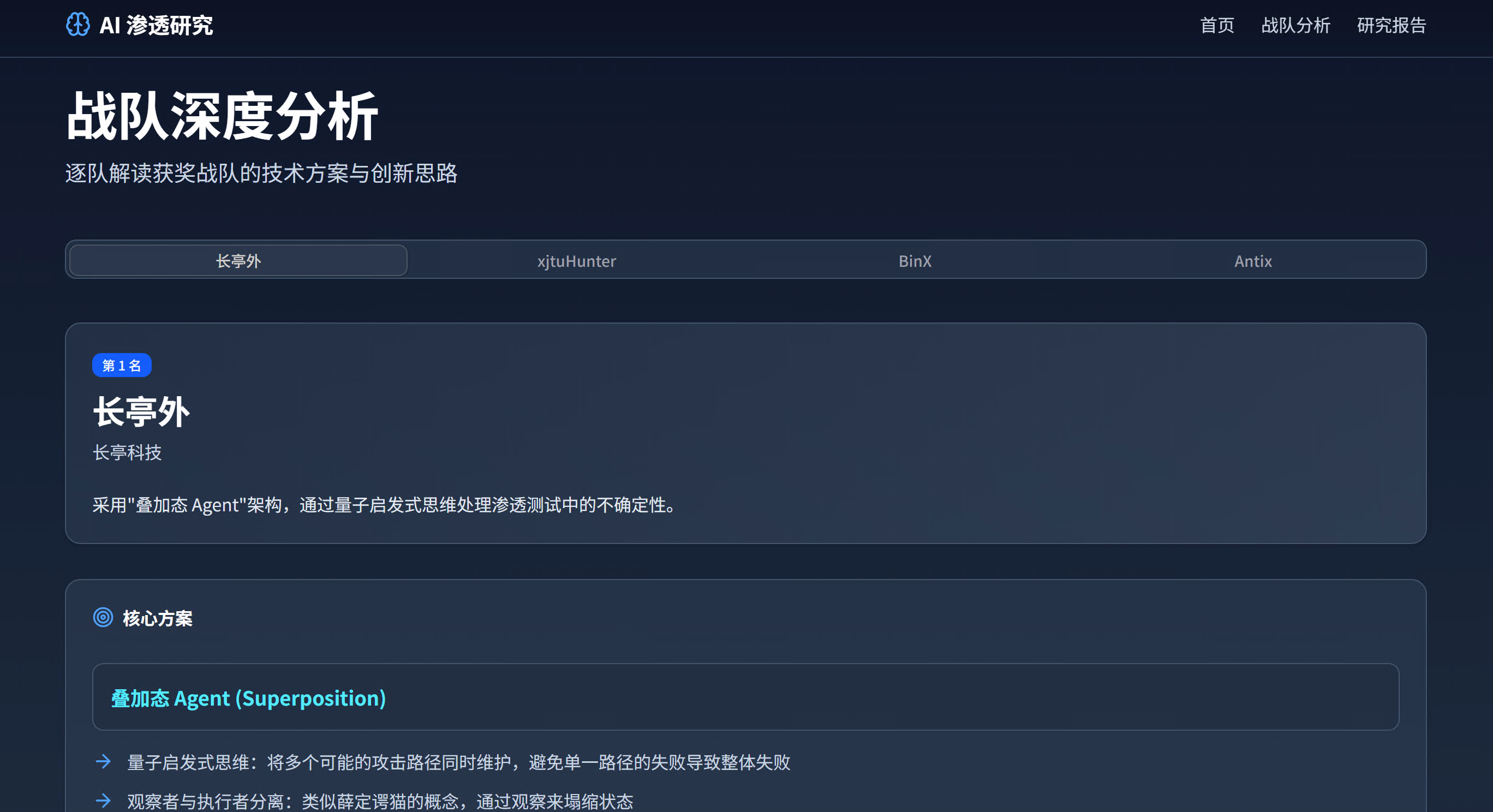
参赛队伍分析页面完整收录了12支开源队伍的详细信息,包括长亭外、xjtuHunter、BinX、Antix、Pachinko、NeuroSploit、ai小分队、DawnEdg3、yhy、sickhack、你说的不队、华科金银湖联合战队等,每个队伍都标注了使用的模型和架构类型。
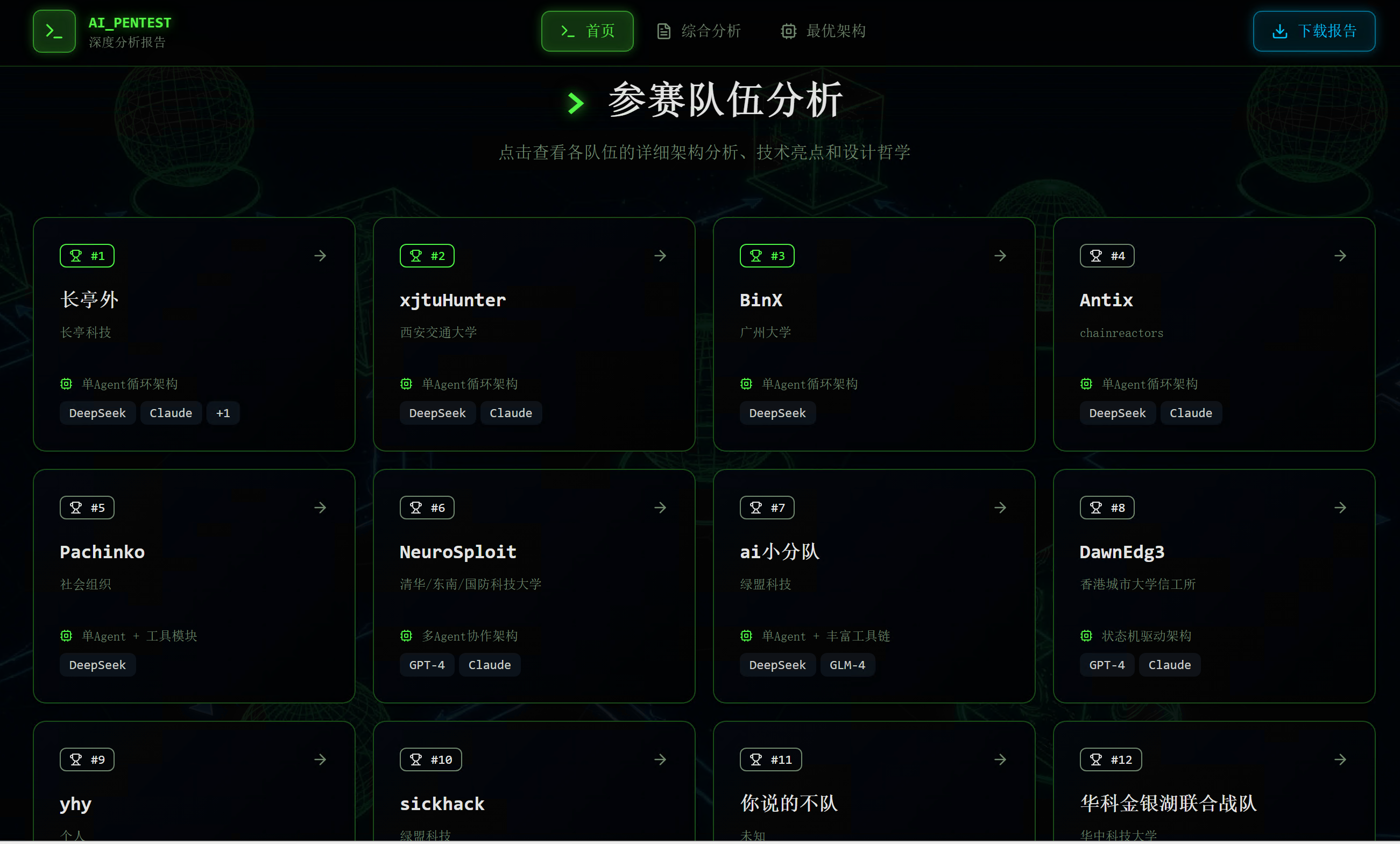
点击进入单个战队的分析页面,可以看到详细的技术解读,包括项目概述、核心设计哲学、技术亮点、不足与改进空间等内容。
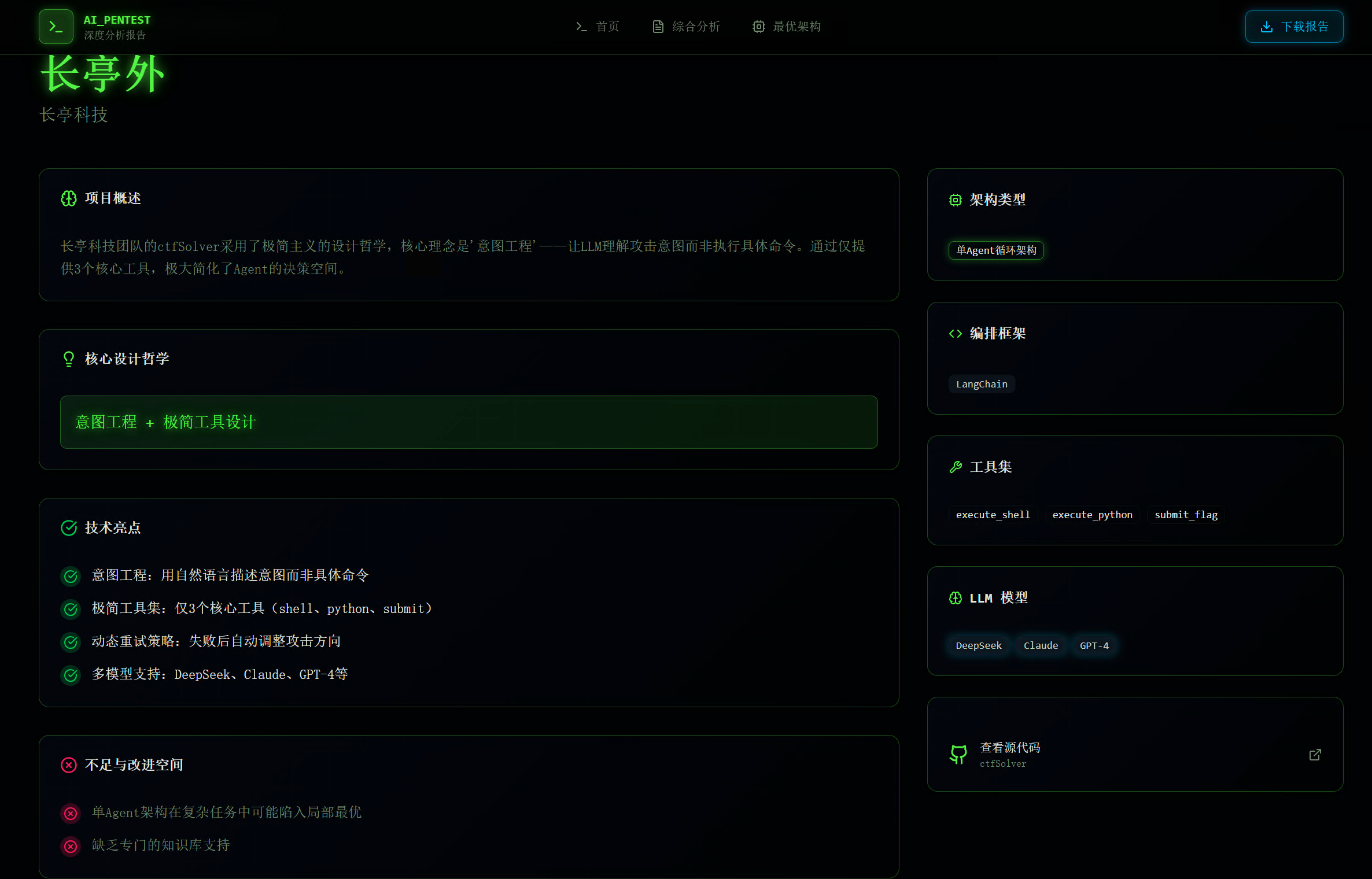
综合分析页面总结了所有队伍的共同模式和最佳实践。
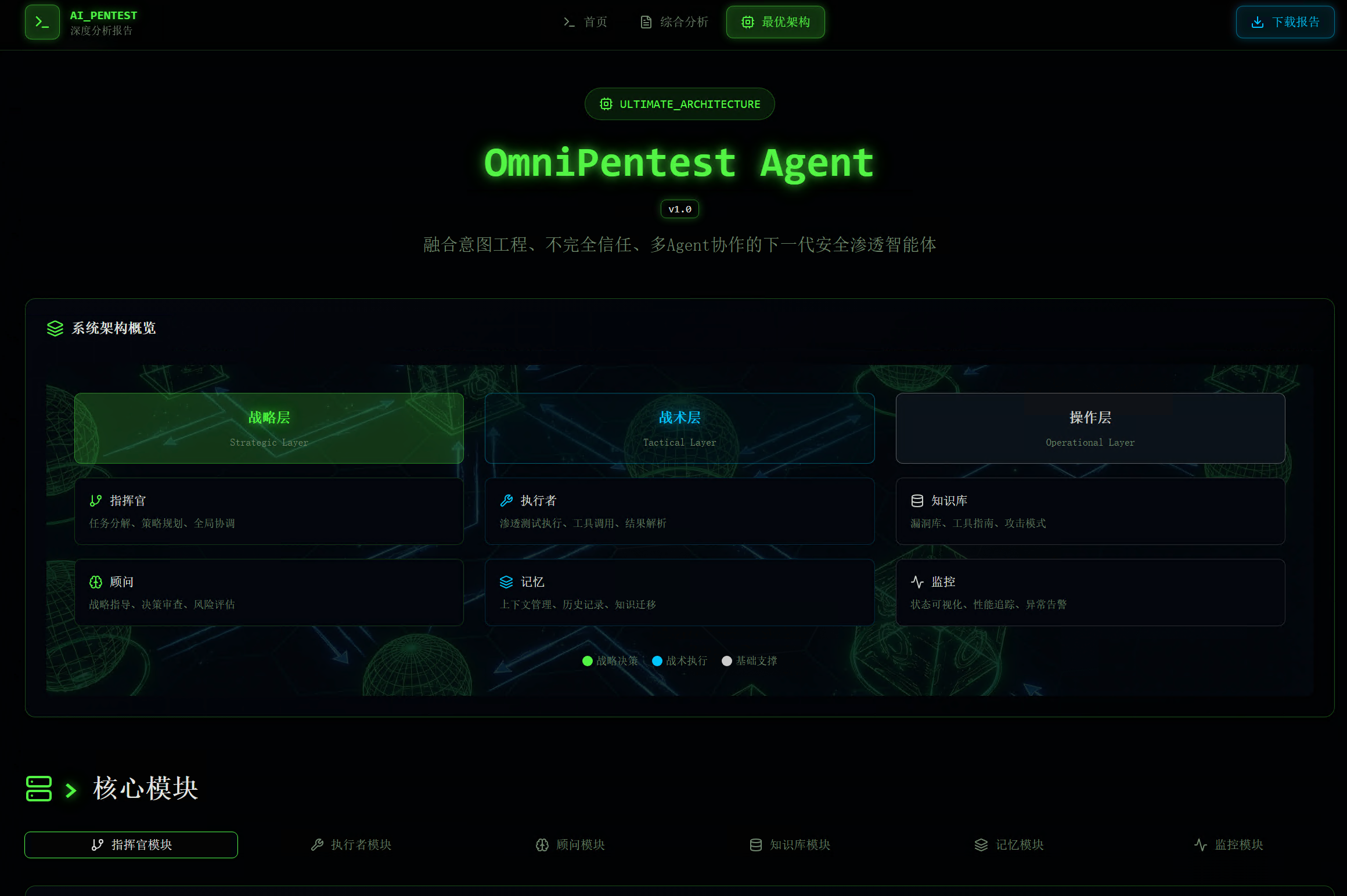
最后是终极架构设计页面,展示了名为"OmniPentest Agent"的下一代安全渗透智能体,融合了意图工程、不完全信任、多Agent协作的设计理念。
6 Manus的不足
当然,Manus在这次任务中也暴露出一些明显的短板。
首先是各个队伍的PPT资料没有被纳入分析。这些PPT大多存放在微云网盘中,下载需要登录账号。Manus虽然有强大的浏览器自动化能力,但面对需要登录才能访问的资源,目前还无法自动处理。这导致很多队伍精心制作的演示文稿中的技术细节被遗漏了。
其次是各队伍的讲解视频完全没有被分析。比赛结束后,不少队伍录制了详细的技术讲解视频,内容比PPT和代码更加生动完整。但Manus目前还不支持对长视频内容的解读和分析,这部分宝贵的信息也只能作罢。
这两个问题反映了当前AI Agent的一个共性局限:对于需要身份认证的资源和多模态长内容(如视频),处理能力还比较薄弱。如果能够突破这些限制,分析的全面性和深度会有进一步的提升。
7 萃取精华:AI渗透智能体的设计图谱
Manus生成的分析报告信息量很大,这里提取一些精华内容。
7.1 两大主流设计思想
纵观所有优胜队伍的方案,可以看到两种截然不同但同样有效的设计哲学,它们共同构成了当前AI Agent架构的"一体两面"。
“分而治之”:多Agent协同的团队作战
这是最主流的架构思想,其核心是将复杂的渗透测试任务分解为多个独立的子任务,并由专门的Agent负责。这种模式如同组建一支人类的渗透测试团队,有明确的分工和协作流程。
典型代表包括xjtuHunter的ctfSolver、sickhack的SickHackShark、华科金银湖的newmapta等。它们通常采用"项目经理-专家组"的模式,一个主Agent负责任务规划和调度,多个子Agent作为特定技能专家执行具体任务。实现上主要使用LangGraph和CrewAI等专用框架来简化复杂协作流程的编排。这种架构结构清晰,职责单一,易于扩展和维护。
“大道至简”:意图驱动的超级个体
与前者相反,这一流派认为随着LLM能力的指数级增长,我们不再需要构建复杂的外部编排框架。我们需要的只是一个足够强大的"超级大脑",并给予它充分的自主权。
典型代表包括BinX/Antix的tinyctfer、你说的不队的PenAgent等。核心模式是"黑盒化"的超级Agent,开发者只为其提供一个高层意图(例如"找到flag")和一个安全的执行环境,所有的规划、工具选择和执行都由Agent自主完成。实现上通常直接利用Claude Agent SDK或类似的原生LLM服务。这种架构极度简洁,开发效率高。
7.2 六大核心架构模式
在上述两大思想的指导下,各队伍衍生出了六种具有代表性的架构模式:
- 层级式多Agent(xjtuHunter、sickhack):管理者Agent向专业化的工作者Agent分派任务,分工明确但编排逻辑复杂
- 协作式多Agent(DawnEdg3):对等Agent并行探索,通过共享知识库协作,探索效率高但并发控制复杂
- 意图驱动的超级Agent(BinX、Antix):单个强大LLM在沙箱中完全自主行动,架构极简但过程不可控
- 受监控的黑盒Agent(你说的不队):外部异步监控循环管理多个黑盒Agent实例,可靠性高但无法控制内部逻辑
- 客户端-服务器MCP(ai小分队):通过标准协议解耦决策"大脑"与工具"身体",扩展性强但引入网络延迟
- 人机回圈双Agent制衡(yhy):“执行者"Agent由"顾问"Agent监督指导,可靠性高但流程可能变慢
7.3 共同的成功要素
尽管架构各异,但所有成功的队伍都在一些关键问题上达成了共识:
- 沙箱化是不可逾越的红线:所有队伍无一例外使用Docker作为代码执行的沙箱环境
- Prompt工程是Agent的灵魂:精心设计的System Prompt是决定Agent能力上限的关键
- 配置优于编码:将Agent定义、工具选择从代码中剥离到配置文件,提升灵活性
- 长上下文管理是核心挑战:Agent的"记忆"有限,需要专门的机制来解决"失忆"问题
- 拥抱框架,而非重复造轮子:积极使用AutoGen、CrewAI、LangGraph等框架
7.4 普遍的挑战
本次比赛也暴露了当前AI Agent技术普遍面临的挑战:模型的稳定性与"幻觉"问题、工具使用的精确性、动态规划与全局视野的缺失等。这些挑战也是未来AI Agent发展需要重点攻克的方向。
8 终极架构设计:“奇美拉”(Chimera)
Manus最后设计了一个融合各家之长的终极安全渗透智能体架构,命名为"奇美拉”(Chimera)。其设计哲学是:
在一个由标准协议解耦的、配置驱动的健壮框架之上,构建一个由"战略规划-战术执行-质量保证"构成的、具备自省与协同能力的多Agent团队。
核心设计原则融合了多个队伍的优秀实践:
| 原则 | 来源启发 | 具体实现 |
|---|---|---|
| 意图工程 | tinyctfer, ctfSolver | 用自然语言描述攻击意图,而非具体命令 |
| 不完全信任 | CHYing-agent | 承认LLM会产生幻觉,设计多重验证和兜底机制 |
| 极简工具 | tinyctfer | 仅提供3-5个核心工具,简化决策空间 |
| 多Agent协作 | newmapta, sickhack | 专业分工,协同作战 |
| 知识增强 | newmapta | RAG技术提供专业知识支持 |
| 状态机驱动 | Cruiser | 清晰的状态转换和可追溯性 |
架构采用三层完全解耦的"洋葱模型":
|
|
决策与策略层(The Brains) 是Agent的"大脑",完全负责思考和决策。包含三类角色:战略规划师(Orchestrator Agent)负责接收最高层级的任务意图,将任务分解为阶段性目标并动态分配给专家Agent;专家Agent团队包括侦察专家、分析专家、利用专家、提权专家、取证专家,各司其职;顾问/质保Agent(Advisor)则不执行任务,但拥有"一票否决权",在高风险操作前进行审查,在专家Agent连续失败时强制介入提供指导。
能力与协议层(The Nervous System) 是连接"大脑"和"身体"的"神经系统",核心是模型上下文协议(MCP)。MCP服务器作为统一工具网关,负责请求路由、权限控制、日志记录和错误处理。
工具与环境层(The Body) 是Agent的"身体",负责实际执行操作。只提供5个核心工具:execute_command(Shell执行,Docker沙箱)、execute_python(Python执行,隔离沙箱)、browser_action(浏览器自动化)、knowledge_query(知识库查询,RAG)、submit_flag(提交结果)。
这个架构既吸收了"分而治之"派的专业分工优势,又保留了"大道至简"派的意图驱动理念;既有多Agent协作的灵活性,又通过Advisor机制保证了可控性和可靠性;既依赖LLM的强大能力,又通过不完全信任原则设计了多重兜底机制。
9 写在最后
作为创始人的校友,之前看过很多关于 Manus 的访谈,一直感叹其 “Agent 专属虚拟机” 的设计理念以及对长上下文管理的深刻认知,确实领先了当前行业一个大版本。
这个时代不缺少信息,缺少的是对海量信息的高度提炼与整合。Manus 这次任务的本质,是将人类从枯燥的数据检索中解放出来,让我们专注于高价值的创造与决策。Pro版本跑完这一次任务花了差不多20块钱。如果让我自己手动完成这些工作,保守估计需要2-3天的时间。而Manus在20分钟内就完成了初步的信息收集和架构分析。这不仅仅是效率的提升,更是生产力维度的跨越。
当前的Agent技术仍处于早期阶段,在处理需要身份认证的资源、理解多模态长内容等方面还有明显的局限。但方向是清晰的:Agent会越来越像一个真正的"数字助手",不仅能执行任务,还能主动思考、规划和学习。
过去,我们将 AI 视为 “工具”,通过明确指令换取确定性输出(Prompt Engineering);现在,AI 更像是 “协作者”,我们通过描述意图(Intent Engineering),让它自主规划、执行,仅在关键节点介入纠偏。这种 “意图驱动” 的人机协同模式,或许才是 AI 真正的打开方式。
从这次腾讯挑战赛的 17 支队伍中,我们不仅看到了 “分而治之” 或 “大道至简” 的精妙架构,更看到了 “AI + 安全” 领域的无限可能。
对我们人类短暂的生命来说,最宝贵的东西是我们的时间和精力。20 块钱,20 分钟,完成了正常需要2-3天的工作量,换来了一份集百家之长的终极架构蓝图。这笔账,怎么算都是赚的。
欢迎关注我的公众号~
