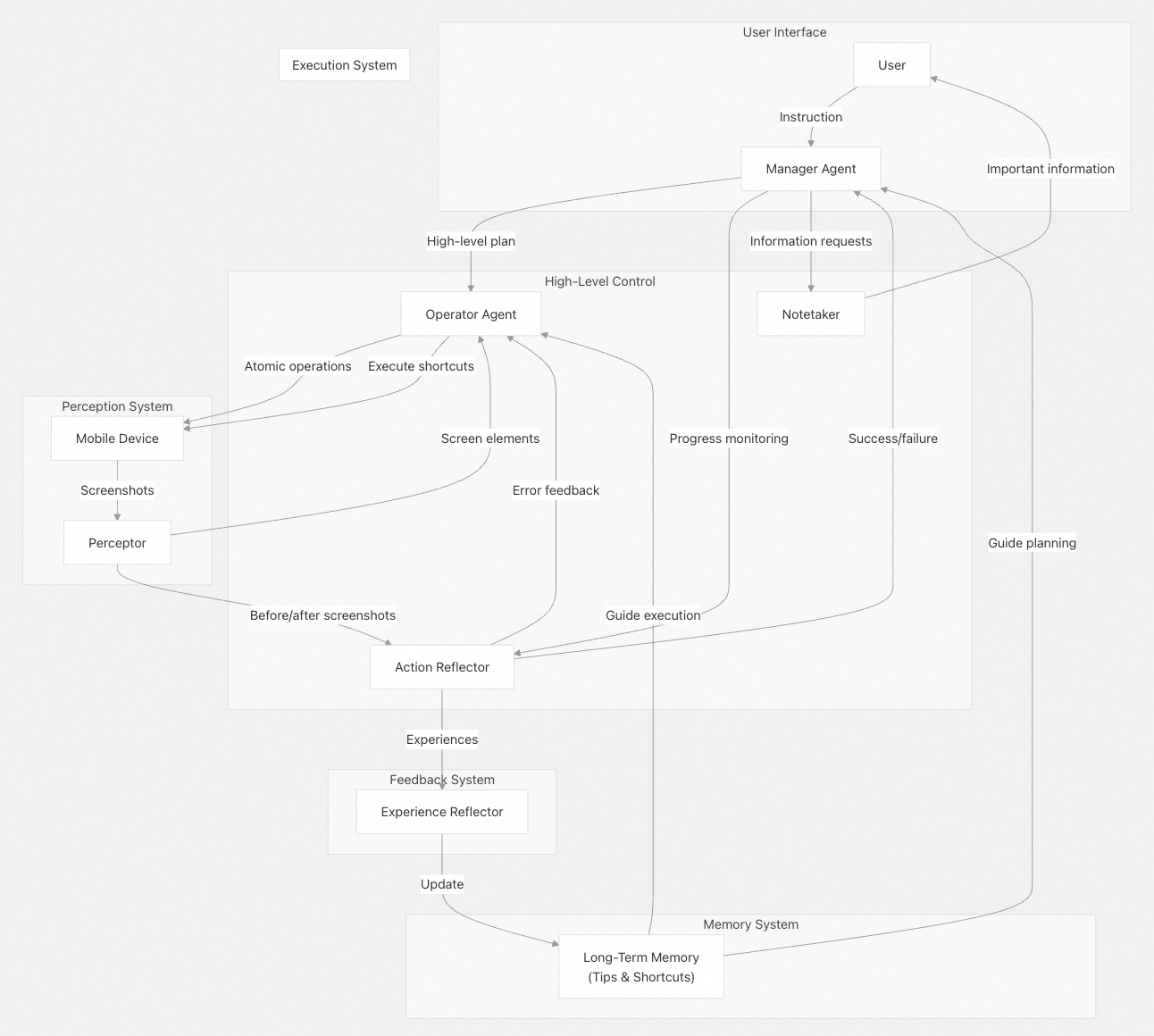
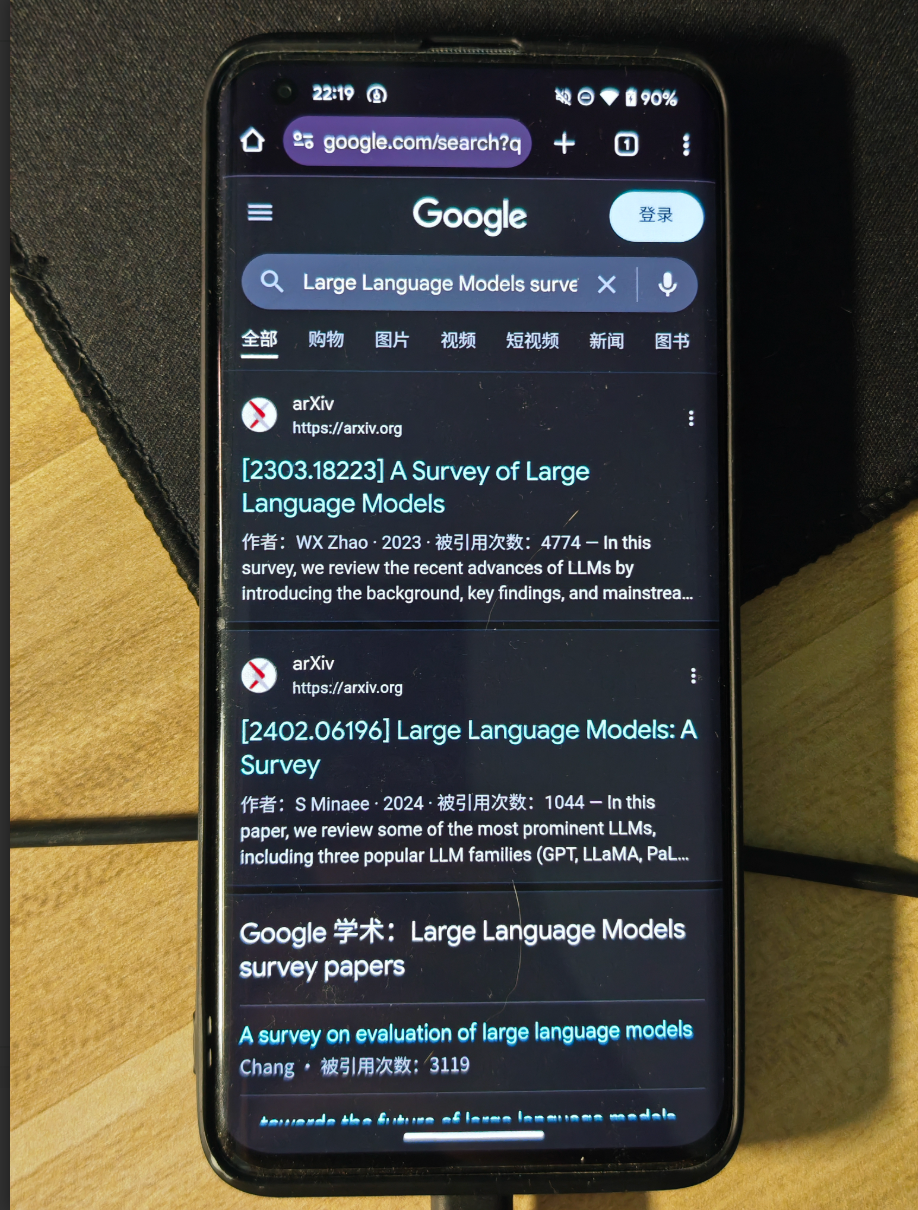
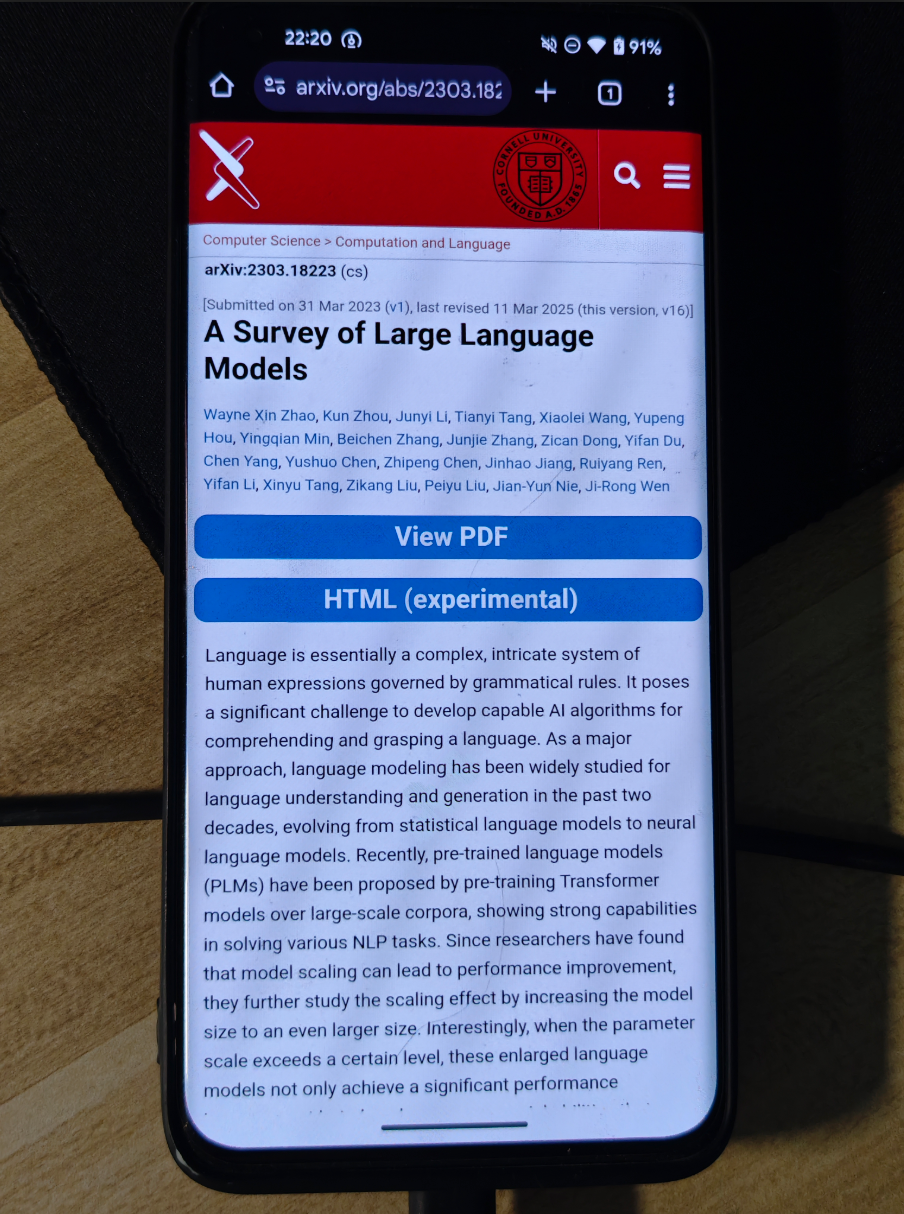
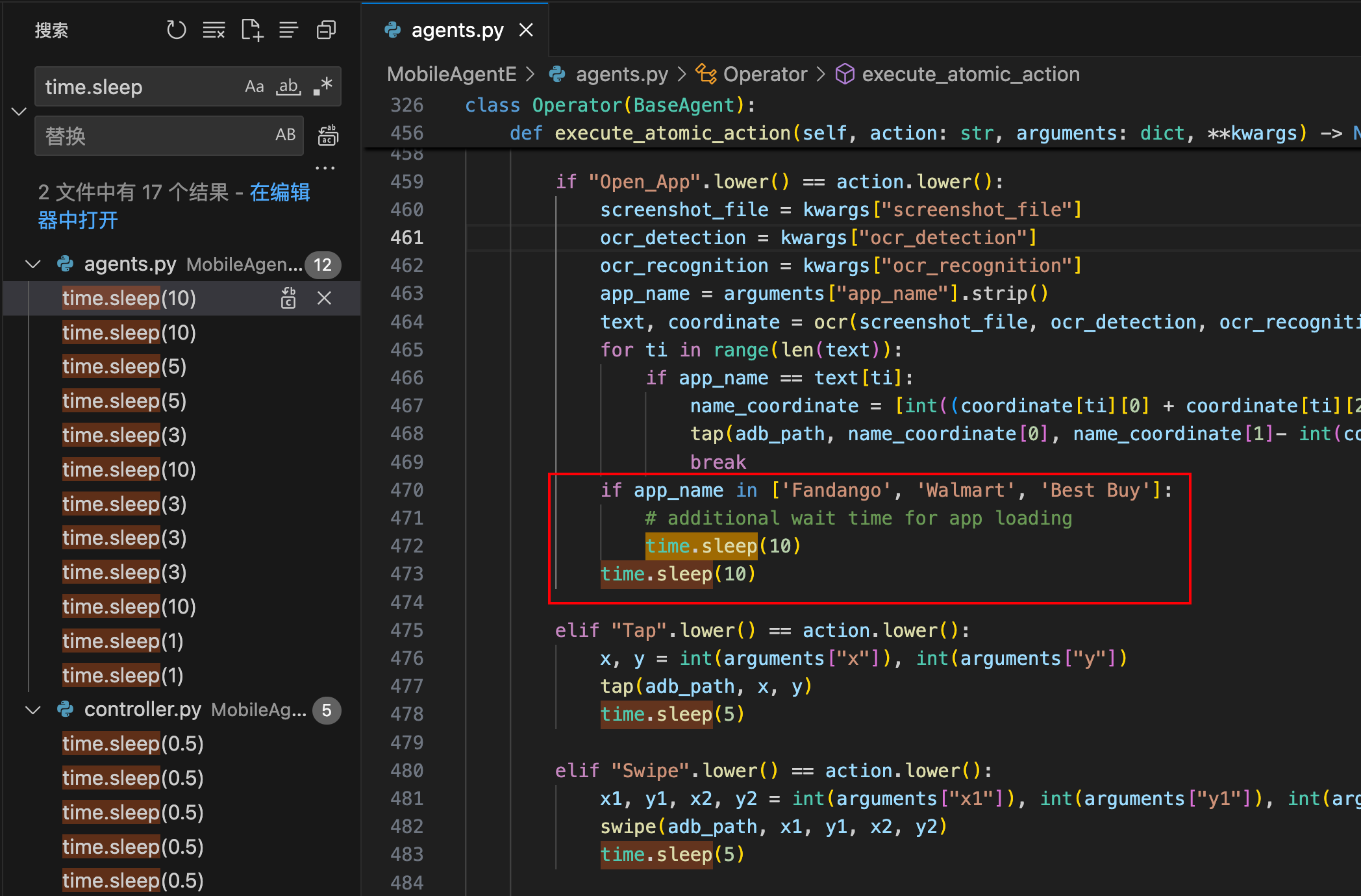
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
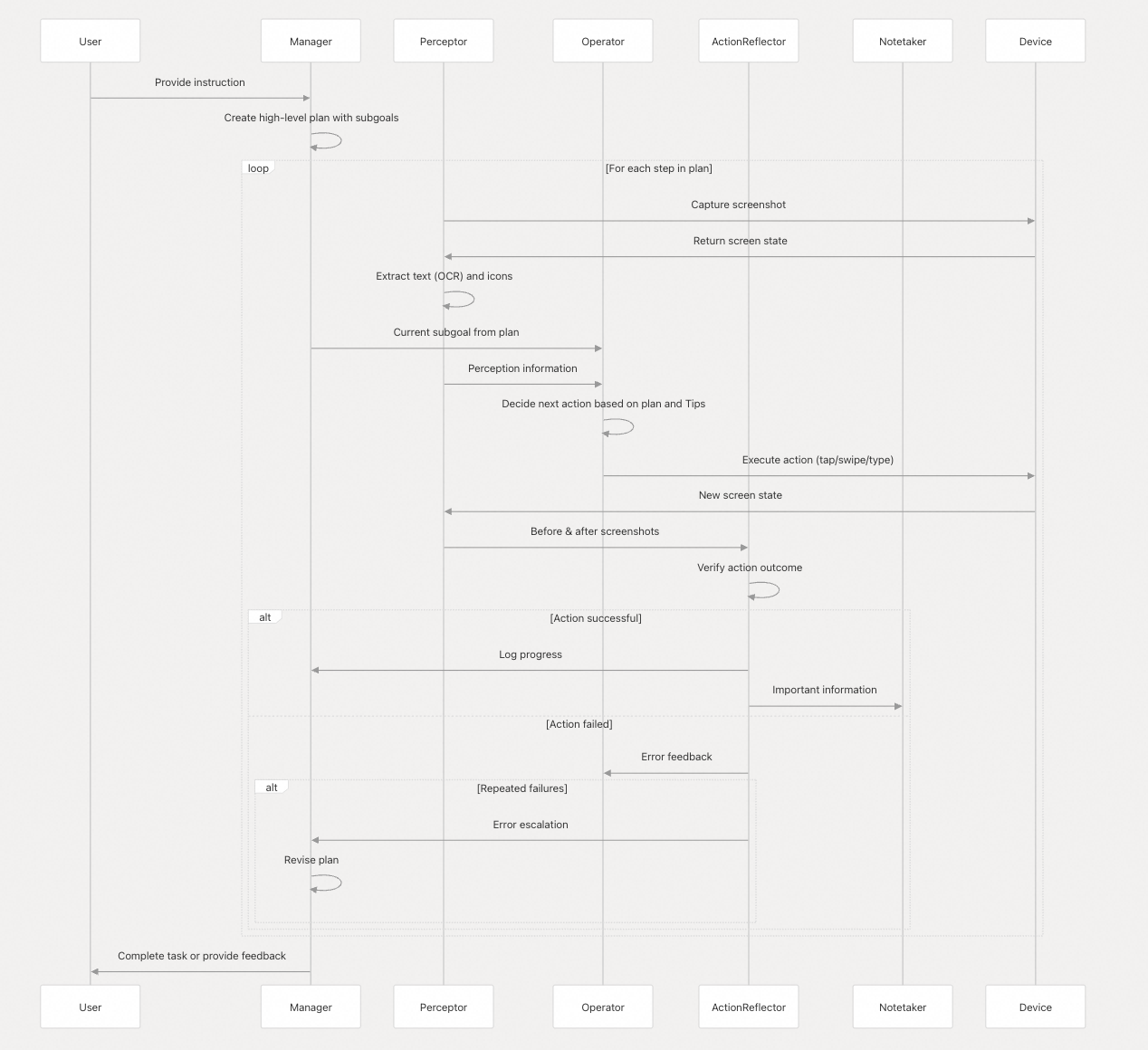
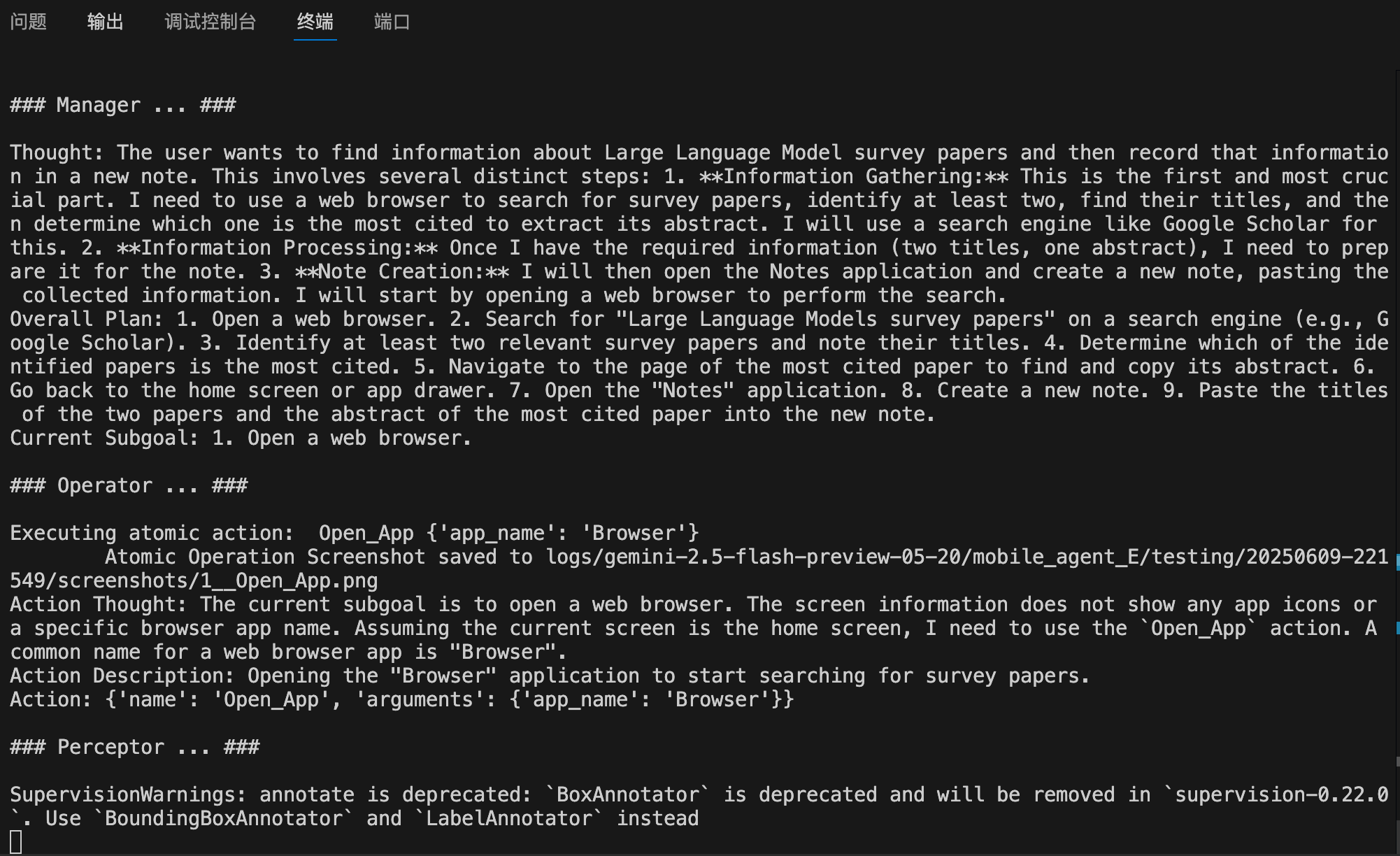
### Manager ... ###
Thought: The current subgoal is to open the Chrome browser. I can see the Chrome icon on the home screen. I will tap on the Chrome icon to open the browser.
Overall Plan: 1. Open the Chrome browser. 2. Navigate to the blog `yzddmr6.com`. 3. Read the content of the first three articles on the blog. 4. Generate a summary of the content from the three articles. 5. Open the file manager (MT管理器). 6. Create a new text file named `blog.txt` and save the generated summary into it.
Current Subgoal: 1. Open the Chrome browser.
### Operator ... ###
Executing atomic action: Tap {'x': 745, 'y': 1963}
Atomic Operation Screenshot saved to logs/gemini-2.5-flash-preview-05-20/mobile_agent_E/testing/20250614-105247/screenshots/2__Tap.png
Action Thought: My previous attempt to open Chrome using `Open_App` failed, indicating that the app name "Chrome" might not be recognized or directly available for that action. Looking at the screenshot, I can see the Chrome browser icon at coordinates [745, 1963]. To open the browser, I will directly tap on this icon.
Action Description: Tap the Chrome browser icon to open the application. This is a direct way to launch the app when `Open_App` fails or the app name is not explicitly listed.
Action: {'name': 'Tap', 'arguments': {'x': 745, 'y': 1963}}
### Perceptor ... ###
SupervisionWarnings: annotate is deprecated: `BoxAnnotator` is deprecated and will be removed in `supervision-0.22.0`. Use `BoundingBoxAnnotator` and `LabelAnnotator` instead
Perception Infos: [{'text': 'text: 91%', 'coordinates': [956, 60]}, {'text': 'text: @', 'coordinates': [335, 62]}, {'text': 'text: 10:54', 'coordinates': [246, 61]}, {'text': 'text: 40', 'coordinates': [753, 62]}, {'text': 'text: e', 'coordinates': [801, 62]}, {'text': 'text: O', 'coordinates': [63, 167]}, {'text': 'text: i', 'coordinates': [1014, 166]}, {'text': 'text: 0', 'coordinates': [881, 167]}, {'text': 'text: Google', 'coordinates': [535, 336]}, {'text': 'text: 搜索或输入网址', 'coordinates': [283, 560]}, {'text': 'text: f', 'coordinates': [834, 851]}, {'text': 'text: 虎', 'coordinates': [613, 852]}, {'text': 'text: 虎扑', 'coordinates': [612, 965]}, {'text': 'text: 百度', 'coordinates': [187, 966]}, {'text': 'text: Gitl', 'coordinates': [1012, 965]}, {'text': 'text: YouTube', 'coordinates': [400, 966]}, {'text': 'text: Facebook', 'coordinates': [827, 966]}, {'text': 'text: 探索', 'coordinates': [125, 1186]}, {'text': 'text: 8', 'coordinates': [937, 1194]}, {'text': 'text: X', 'coordinates': [915, 1330]}, {'text': 'text: 获得更合平需求的内容', 'coordinates': [539, 1485]}, {'text': 'text: 登录即可获取系统根据您的兴趣推荐的内容', 'coordinates': [539, 1573]}, {'text': 'text: 以6的身份继续', 'coordinates': [540, 1694]}, {'text': 'text: 选择其他账号', 'coordinates': [536, 1825]}, {'text': 'text: 用了几十年才刚知道,\n塑料椅中间的小洞是这', 'coordinates': [361, 2074]}, {'text': 'text: 么用的,涨知识了', 'coordinates': [303, 2172]}, {'text': 'text: i', 'coordinates': [966, 2266]}, {'text': 'text: 阿波罗新闻网·1日', 'coordinates': [290, 2269]}, {'text': 'icon: The icon is a blue square with a white paw print in the center.', 'coordinates': [186, 847]}, {'text': 'icon: The icon is a square with rounded corners, featuring a red background and a white play button in the center.', 'coordinates': [399, 847]}, {'text': 'icon: The icon is a teal circle with the number 6 in white.', 'coordinates': [538, 1356]}, {'text': 'icon: The icon is a blue square with rounded corners, featuring the white lowercase letter "f" in the center.', 'coordinates': [824, 847]}, {'text': 'icon: The icon is a simple, black house shape with a triangular roof on a white background.', 'coordinates': [65, 166]}, {'text': 'icon: The icon is a dark purple circle with a white camera outline inside it.', 'coordinates': [935, 560]}, {'text': 'icon: The icon is a yellow sun with rays extending outward, set against a white background.', 'coordinates': [109, 2265]}, {'text': 'icon: The icon depicts four orange plastic stools arranged in a square formation.', 'coordinates': [848, 2101]}, {'text': 'icon: The icon is a simple, rounded square with a white microphone symbol in the center, set against a dark gray background.', 'coordinates': [803, 560]}, {'text': 'icon: The icon is a square with rounded corners, colored black and white, featuring the number "1" in the center.', 'coordinates': [880, 166]}, {'text': 'icon: The icon is a black circle with a smaller white circle in the center, resembling an eye or a simplified face.', 'coordinates': [743, 165]}, {'text': "icon: The icon features a stylized, simplified shape of a tiger's head in black against a white background.", 'coordinates': [613, 848]}, {'text': 'icon: The icon is a circular shape with a dark background and features the red Chinese character "虎" (tiger) in the center.', 'coordinates': [612, 847]}, {'text': 'icon: The icon is a white, stylized word "Google" on a black background.', 'coordinates': [535, 337]}, {'text': 'icon: The icon is a black, X-shaped symbol on a white background.', 'coordinates': [913, 1327]}, {'text': 'icon: The icon is a black, circular shape with two smaller circles connected by lines, resembling a share symbol.', 'coordinates': [833, 2265]}, {'text': 'icon: The icon is a square with rounded corners, featuring a red play button on a white background, set against a dark circular backdrop.', 'coordinates': [399, 847]}, {'text': 'icon: The icon is an oval shape with a light purple background.', 'coordinates': [539, 1693]}, {'text': 'icon: The icon is a circular shape with a white background and a black outline, featuring a small vertical line in the center.', 'coordinates': [335, 62]}, {'text': 'icon: The icon depicts two orange, square-shaped stools stacked on top of each other.', 'coordinates': [777, 2090]}, {'text': 'icon: The icon depicts a simple, orange stool with a square seat and four legs.', 'coordinates': [823, 2128]}, {'text': 'icon: The icon features a simple, orange stool with a circular seat and four square legs.', 'coordinates': [935, 2120]}, {'text': 'icon: The icon is a simple, black Chinese character "探索" (exploration) on a white background.', 'coordinates': [125, 1185]}, {'text': 'icon: The icon features a square shape with rounded edges, colored in a bright orange hue.', 'coordinates': [884, 2052]}, {'text': 'icon: The icon is a simple, bold numeral "6" in black against a white background.', 'coordinates': [539, 1355]}, {'text': 'icon: The icon is a black circle with a diagonal line crossing through it, indicating prohibition or cancellation.', 'coordinates': [751, 61]}, {'text': 'icon: The icon is a white semicircle on a black background.', 'coordinates': [853, 60]}, {'text': 'icon: The icon is a square with rounded corners, featuring the letter "f" in white on a blue background.', 'coordinates': [824, 846]}, {'text': 'icon: The icon is a square with rounded corners, featuring a light blue paw print design and the letters "du" in a darker shade of blue.', 'coordinates': [186, 846]}, {'text': 'icon: The icon is a black square with white Chinese text that reads, "用了几十年才刚知道,塑料椅中间的小洞是这么用的,涨知识了."', 'coordinates': [361, 2106]}, {'text': 'icon: The icon is a circular shape with a dark gray color.', 'coordinates': [1017, 847]}, {'text': 'icon: The icon is a simple black circle with a horizontal line through the center, indicating a cancel or stop function.', 'coordinates': [800, 61]}]
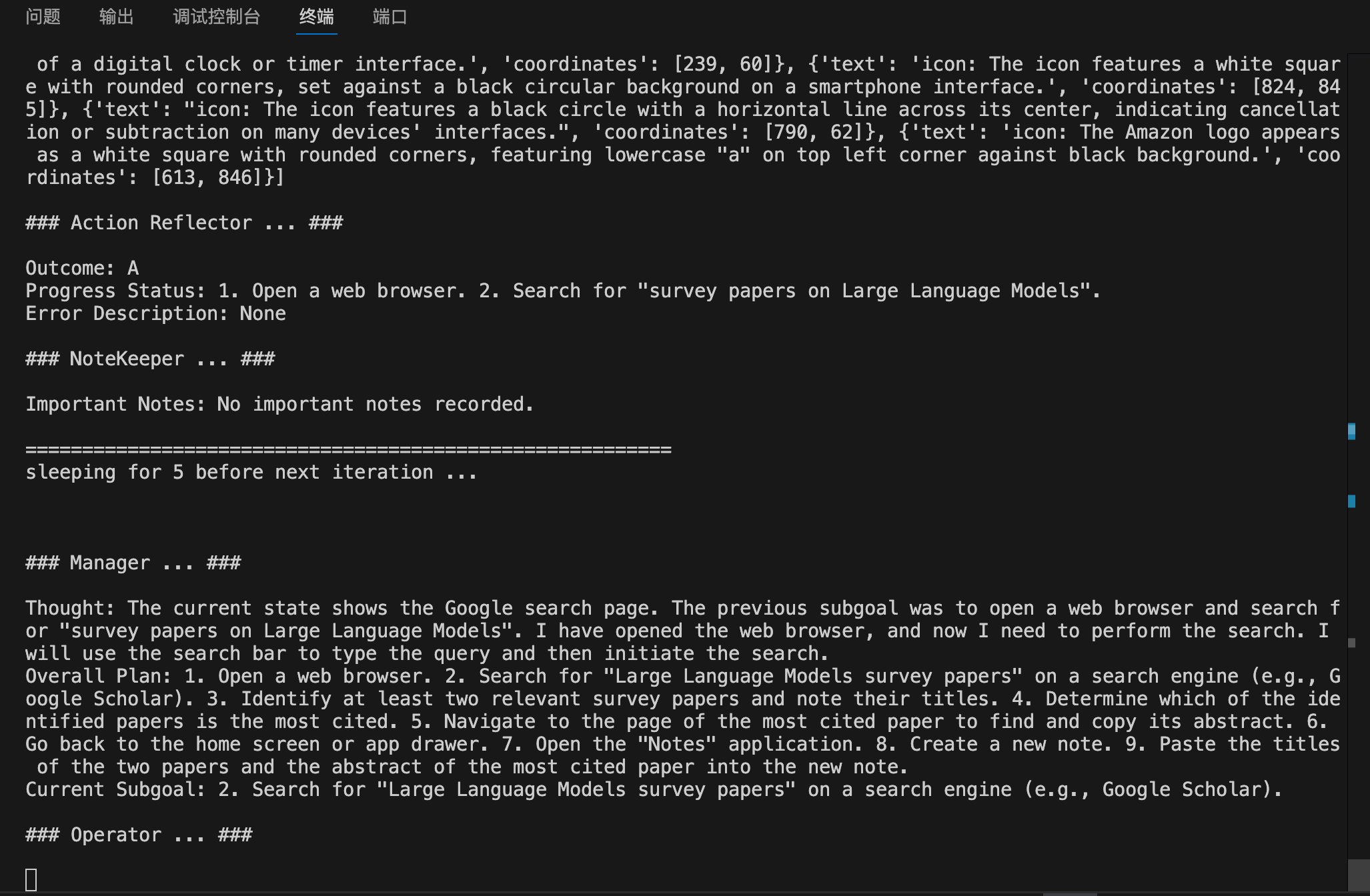
### Action Reflector ... ###
Outcome: A
Progress Status: 1. Open the Chrome browser. 2. Navigate to yzddmr6.com.
Error Description: None
### NoteKeeper ... ###
Important Notes: - The Chrome browser is open and displaying the Google search page. - There is a search/URL input field labeled "搜索或输入网址" (Search or enter URL) at coordinates [283, 560].
=========================================================
sleeping for 5 before next iteration ...
|